Given we’ve received a number of inquiries as for the agenda of this year’s TelcoSecDay here’s a first preliminary agenda. To get an idea of the event’s character you might have a look at the agenda of the 2012 edition or the 2013 edition. Pls note that there might be changes/additions to the following outline as we’re currently discussing potential contributions with two European operators. Here we go, for today:
9:00: Opening Remarks & Introduction
9:15: Ravi Borgaonkor – Evolution of SIM Card Security
10:15: Break
10:45: Adrian Dabrowski
11:45: Collin Mulliner – PatchDroid – Third Party Security Patches for Android
12:30: Lunch
13:45: Philippe Langlois
14:45: Break
15:15: Haya Shulman – The Illusion of Challenge-Response Authentication
16:00: Christian Sielaff & Daniel Hauenstein – Breaking Network Monitoring Tools Used in Telco Space
16:30: Closing Remarks
19:00: Joint dinner (hosted by ERNW) in Heidelberg Altstadt for those interested and/or staying for the main conference
Some of you may already know (the ones who are following Enno on Twitter) that Enno and I had our lab day in preparation for the IPv6 Security Summit at Troopers. We had a brand new and shiny Cat4948E as our lab device to do some testing of the current generation of Cisco’s IPv6 First Hop Security (FHS) mechanisms. The Catalyst was running the latest image available (15.1(2)SG3).
In this small blog post, we will take a look at the configuration and behavior of IPv6 Snooping and DHCPv6 Guard. So let’s start with IPv6 Snooping:
Hey guys,
as some of you may have noticed, just recently at ShmooCon we gave our talk “LTE vs. Darwin” (Slides here). There we presented some results of our research in 4G telco network security. Some of those originate from our research contribution to ASMONIA, but we expanded the scope and also took a look at the air interface. Both the air interface and the backend links & protocols must be secured appropriately; otherwise communication may be eavesdropped or sensitive information may be compromised. In the following we want to provide an overview of LTE main components and potential attack vectors. Continue reading “LTE@ShmooCon, a Summary”
Last weekend, from 17 to 19 January, ShmooCon was held in Washington, DC. A number of different topics was covered in great talks and we want to give you a short overview of the conference. In the following our favorite talks are briefly summarized.
We just got credits for a flaw we found in SAP Netweaver. The issue is a reflected Cross-Site Scripting (XSS). It can be triggered in the administrative interface for the Internet Communication Manager (ICM) and Web Dispatcher. This means that the targets for this XSS will definitely be users with administrative privileges. This makes it especially juicy for an attacker. Continue reading “XSS in SAP Netweaver”
This is the second part of the – presumably – three-part series on IPv6 address planning which I started here.
Before an enterprise organization (strictly speaking “their internal service provider acting as LIR”, as laid out in the first part) starts assigning prefix[es]/lengths to their networks usually another discussion has to be undertaken & solved: “go with one /32 [PI space] from one RIR or apply for /32s from several RIRs”.
The background of this reflection is mainly them being concerned along the lines: how do we know if $PROVIDER in some part of the world is actually going to route our PI space, in particular if that’s allocated from ‘a foreign RIR’?
Today we have to pleasure to announce another round of Troopers talks.
Here we go:
Noam Liram: Vulnerability Classification in the SaaS Era FIRST TIME MATERIAL
Abstract: In this talk we will thoroughly analyze two major SaaS vulnerabilities that were found by Adallom (one of which is still in responsible disclosure stages at the time of writing). By demonstrating this new class of exploits which we have nick-named “Ice Dagger” attacks, we aim to change the current industry-wide criteria for vulnerability classifications, which were developed in the Desktop/Server world, are inadequate when classifying SaaS vulnerabilities. We will specifically discuss the details of MS13-104.
Bio: Noam Liran is the Chief Software Architect of Adallom, a SaaS application security provider. Noam is an alumnus of Israel Defense Force’s Unit 8200 and was a team leader in its cyber division.
===
Vladimir Katalov: Modern Smartphone Forensics – Apple iOS: from logical and physical acquisition to iCloud backups, document storage and keychain; Encrypted BlackBerry Backups (BB 10 and Olympia Service)
Abstract:
Apple iCloud Backups: there are various methods to perform data acquisition from iOS devices: logical, advanced logical (using hidden services running in iOS) and physical. iCloud analysis is the further step. The iCloud may contain complete device backups (for all devices connected to Apple ID), geolocation data (Find My Phone data), documents, and additional data saved by 3rd party applications. We show how (and where) this data is actually stored, how to request and decrypt it, and how to analyse it. Some information on iCloud keychain is also provided — and yes, sometime there is a way to get all your passwords (including ones from the other devices) and credit card data. And yes, most data is available to Apple itself, as well as to Amazon and Microsoft, so probably to three-letter agencies as well.
BlackBerry: For BB 10 devices, backups created with BlackBerry Link are always encrypted, but the encryption is not user-configurable, and there is no way to view the backup contents or even restore from thgs backup to the other device. We have found that encryption keys is being generated by BlackBerry ‘Olympia Service’, based on BlackBerry ID, password, and device PIN. ID and PIN is something we can get from the backup itself, and if we know the password as well, we can generate the series of requests to Olympia service to obtain the key and decrypt the backup. Backlup contains all applications (purchased from AppWorld), their data (such as WhatsApp conversations), device settings, call logs, passwords etc — most in the plain form or SQLite databases.
Bio: Vladimir Katalov is CEO, co-founder and co-owner of ElcomSoft Co.Ltd. Born in 1969 in Moscow, Russia; studied Applied Mathematics at National Research Nuclear University. Vladimir works at ElcomSoft up until now from the very beginning (1990). Now he is driving all the R&D processes inside the company.
===
Sergey Bratus, Javier Vazquez & Ryan Speers: Making (and Breaking) an 802.15.4 WIDS
Abstract: Real-world security-critical systems including energy metering and physical security monitoring are starting to rely on 802.15.4/ZigBee digital radio networks. These networks can be attacked at the physical layer (reflexive jamming or via Packet-in-packet attacks), the MAC layer (dissociation storms), or at the application layers. Proprietary WIDS for 802.15.4 exist, but don’t provide much transparency into how their 802.15.4 stacks work and how they may be tested for evasion.
As the classic Ptacek & Newsham 1998 paper explained, tricks used to evade a NIDS tell us more about how a protocol stack is implemented than any specifications or even the RFCs. For WIDS, evasion can go even deeper: while classic evasion tricks are based on IP and TCP packet-crafting, evading 802.15.4 can be done starting at the PHY layer! We will explain the PHY tricks that will make one chip radio see the packets while the other would entirely miss them regardless of range; such tricks serve for both WIDS testing and fingerprinting.
We will release an open, extensible WIDS construction and testing kit for 802.15.4, based on our open-source ApiMote hardware. ApiMote uses the CC2420 digital radio chip to give you access to 802.15.4 packets at the nybble level. It can be easily adopted for detecting attacks at any protocol level. It also lets you test your ZigBee WIDS and devices from the frame level up. We will give out some of the ApiMotes.
Bios:
Sergey Bratus is a Research Assistant Professor of Computer Science at Dartmouth College. He sees state-of-the-art hacking as a distinct research and engineering discipline that, although not yet recognized as such, harbors deep insights into the nature of computing. He has a Ph.D. in Mathematics from Northeastern University and worked at BBN Technologies on natural language processing research before coming to Dartmouth.
Javier Vazquez is a researcher at River Loop Security specializing in wireless systems, PCB design, and hardware reverse engineering. Javier graduated from the University of Central Florida with a degree in Electrical Engineering and a focus on RF Engineering. Other interests include networking and software development.
Ryan Speers is a co-founder and security researcher at River Loop Security and has extensive experience in IEEE 802.15.4/ZigBee analysis and software and hardware security analysis. He maintains the KillerBee 802.15.4 assessment framework has previously spoken at ShmooCon and ToorCon Seattle, and has published at USENIX WOOT, IEEE/HICSS, and the Workshop on Embedded Systems Security. He enjoys breaking things, although not when volunteering as an EMT or when rock-climbing. He graduated from Dartmouth College with a degree in Computer Science.
===
Martijn Jansen: How to Work towards Pharma Compliance for Cloud Computing – What Do FDA and Similar Regulations Mean for Your (Cloud) IT Delivery Organisation? FIRST TIME MATERIAL
Abstract: Today, for life-sciences or consumer goods manufacturers/food/drug companies’ regulatory compliance is quite a heavy burden to their day-day operation. This applies in particular when business operations or sales are (also) in the US so that a company becomes a regulated entity under the very stringent FDA regime.
The presentation is about the translation of Pharmaceutical regulations (what regulations?) that could be applied to any cloud-related IT service into a quality management strategy and hands-on IT controls that could work for each one of us.
Think of how to bring compliance into the lifecycle of requirements, design, install and configuration plans etc. Furthermore we’ll discuss different types of controls in service creation or delivery, be them administrative, technical, procedural controls. Discussed are usable quality assurance controls for People, Process and Technology, projected onto services (components). These controls might be there already to re-use (but not auditable) or might need to be created.
As one of the first in the industry Martijn will show you, starting at the governance level (to leave no-one behind), examples from the trenches to categorize and map controls on how to utilise Telco and ISO experience best practices. Thus bringing Pharma compliance applicable to IT Cloud Computing down from the academic level to usable hands-on best practices! While compliance is highly theoretical Martijn and thus the material is heavily focussed on real-world usability.
Bio: Martijn has always been intrigued by electronics, transmission and any sort of security since he was a small kid. He built his first FM radio transmitter (after dis-assembling a few) very young, and always kept in touch with electronics and IT.
He is technically educated as construction engineer and -designer. After continued education he served as a diver team commander. Returning back to civilisation he worked in his initial field of expertise (CAD construction design), then turning to IT. Martijn has experience as IT trainer, engineer, architect and consultant in sales, design, implementation and operation of operating systems, networks and security. He auto-didactically studied for about 6 years in the evenings to acquire all the certificates and technologies that were relevant at the time. Till a short while ago, he owned his own 19 inch rack at home with routers, switches and virtualisation computing running.
As a principal consultant and architect Martijn took care of mostly bespoke and complex IT transformations for global pharma and manufacturing customers. He currently works as Security Controls Assurance manager for the Compliance department of a global telco. In this role he looks after compliance and security for the cloud computing proposition.
===
Matthias Luft & Felix Wilhelm: Compromise-as-a-Service: Our PleAZURE FIRST TIME MATERIAL
Abstract: This could be a comprehensive introduction about the ubiquity of virtualization, the essential role of the hypervisor, and how the security posture of the overall environment depends on it. However, we decided otherwise, as this is what everybody is interested in: We will describe the Hyper-V architecture in detail, provide a taxonomy of hypervisor exploits, and demonstrate how we found MS13-092 which had the potential to compromise the whole Azure environment. Live demo included!
Bios:
Matthias Luft is a senior security analyst at ERNW. He has extensive experience in penetration testing and security assessments of complex technical environments. He’s one of the first researchers who revealed major design flaws and vulnerabilities in the approach of Data Leakage Prevention. During the last years, he focused on the area of cloud security and presented both approaches for scalability and trust assessment of cloud service providers. He gives cloud security workshops on a regular base. Furthermore he was the project lead in a research study on a major cloud solution platform which ERNW performed resulting in the discovery of MS13-092. Matthias holds a Master’s degree in computer science from the University of Mannheim.
Felix Wilhelm is a senior security researcher at ERNW. He has extensive experience in performing penetration tests and security assessments of complex technical environments and he is specialized in kernel and virtualization security. Felix has discovered and published multiple critical security vulnerabilities in widely used software and participated in the first Microsoft Bluehat Prize contest to find defense techniques against modern software exploit techniques. Felix gives courses on topics like exploit analysis, reverse engineering and application security. He wrote the Linux kernel code exploiting the MS13-092 vulnerability. Felix holds a Bachelor degree in computer science from the RWTH Aachen University.
===
Juan Perez-Etchegoyen & Will Vandevanter: SAP BusinessObjects Attacks – Espionage and Poisoning of Business Intelligence Platforms
Abstract: Business executives make their strategic decisions and report on their performance based on the information provided by their Business Intelligence platforms. Therefore, how valuable could that information be for the company’s largest competitor? Even further, what if the consolidated, decision-making data has been compromised? What if an attacker has poisoned the system and changed the key indicators?
SAP BusinessObjects is used by thousands of companies world-wide and serves as the gold standard platform for Business Intelligence. In this presentation we will discuss our recent research on SAP BusinessObjects security.
Specifically, through several live demos, we will present techniques attackers may use to target and compromise an SAP BusinessObjects deployment and what you need to do in order to mitigate those risks.
Bios:
Juan Perez-Etchegoyen is the CTO at Onapsis, leading the Research & Development teams that keep the company on the cutting-edge of the ERP security industry. As a renowned thought-leader in the SAP cyber security field, Juan is responsible for the architecture of the innovative software solutions Onapsis X1 and Onapsis IPS.
Being the founder of the Onapsis Research Labs, Juan is actively involved in the coordination and research of critical security vulnerabilities in ERP systems and business-critical applications, such as SAP and Oracle. He has discovered and helped SAP AG fix several critical vulnerabilities. Juan also held the first presentation on advanced threats affecting Oracle’s JD Edwards applications.
As a result of his innovative research work, Juan has been invited to lecture at several of the most renowned security conferences in the world, such as Black Hat, SANS, OWASP AppSec, HackInTheBox, NoSuchCon and Ekoparty. He also holds private trainings for SAP AG and Global Fortune-100 organizations and is frequently quoted and interviewed by leading publications, such as IDG, DarkReading and PC World.
Will Vandevanter is a Senior Security Researcher at Onapsis where he focuses on SAP and ERP security. He has discovered and helped SAP AG patch numerous critical vulnerabilities in SAP software and is a regular contributor to the Onapsis SAP Security In-Depth publication. Prior to Onapsis, Will was the Lead Penetration Tester at Rapid7. He has previously spoken at Defcon, OWASP AppSec, SOURCE Barcelona, and a number of other conferences. Will holds a Bachelors Degree in Mathematics and Computer Science from McGill University and Masters Degree in Computer Science with a focus in Secure Software Engineering from James Madison University.
======
Furthermore there’s some new workshops; just have a look at the agenda 😉
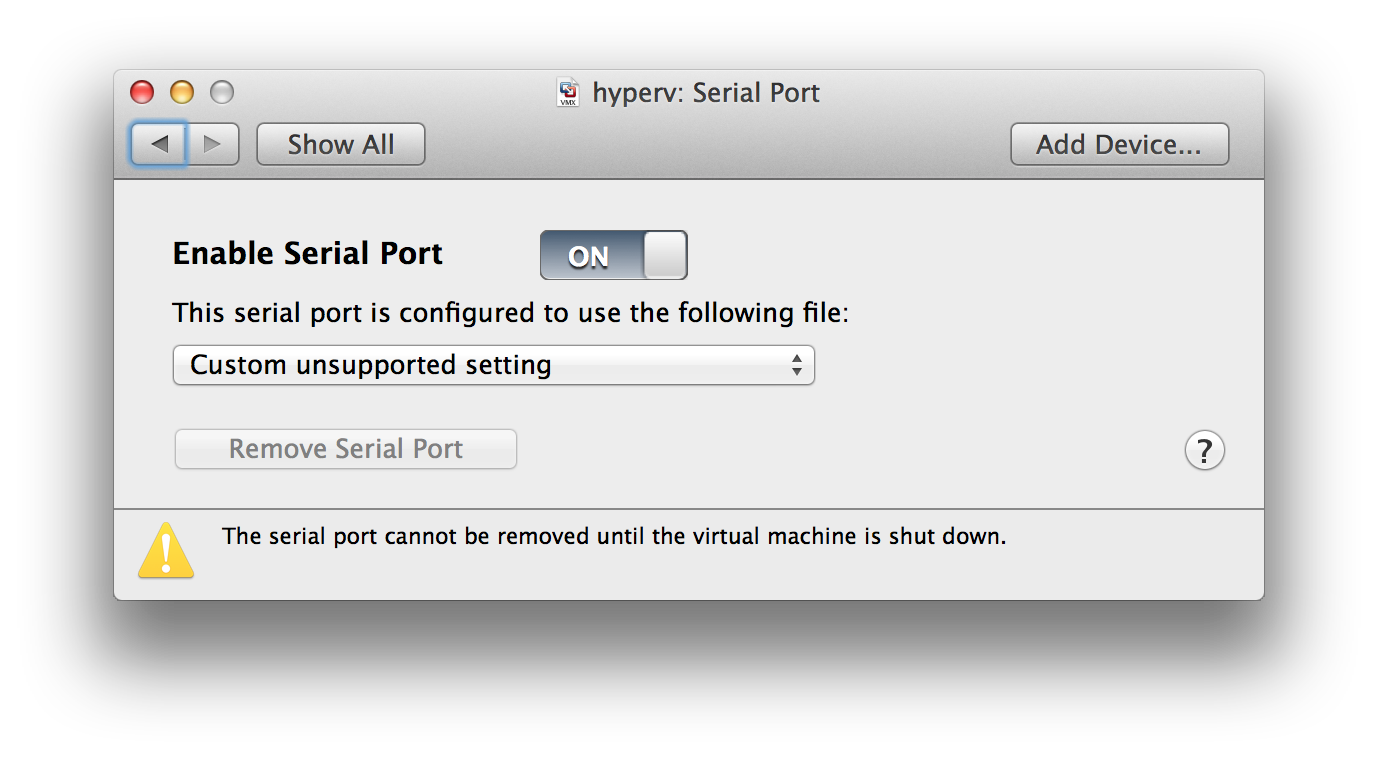
In the course of our virtualization research, we came across a certain technical issue we couldn’t find an easy solution on knowledge bases and the like. However, as we found the question several times on the web, the following post gives just a short hint on a technical detail.
If you want to connect two virtual machines in VMware Fusion using a serial port (e.g. for debugging purposes), Fusion doesn’t provide you an GUI option to configure that. However, if you just add the following config to the debugger system’s VMX file:
During a recent research project we performed an in-depth security assessment of Microsoft’s virtualization technologies, including Hyper-V and Azure. While we already had experience in discovering security vulnerabilities in other virtual environments (e.g. here and here), this was our first research project on the Microsoft virtualization stack and we took care to use a structured evaluation strategy to cover all potential attack vectors.
Part of our research concentrated on the Hyper-V hypervisor itself and we discovered a critical vulnerability which can be exploited by an unprivileged virtual machine to crash the hypervisor and potentially compromise other virtual machines on the same physical host. This bug was recently patched, see MS13-092 and our corresponding post. Continue reading “Exploiting Hyper-V: How We Discovered MS13-092”
continuing our tradition from last year (see here and here), we summarized more of our hardening recommendations for you. This guide is covering Tomcat 7 and is supposed to provide a solid base of hardening measures. It includes configuration examples and all necessary commands for each control, specifically for the most recent branch of Tomcat as there were some significant changes. Download: ERNW_Checklist_Tomcat7_Hardening.pdf