Some weeks ago, at RIPE 68 in Warsaw, Sander Steffann gave a presentation about revising RIPE 554 which, in his own words, “is a template guideline for procurement of stuff that should do IPv6” (here’s the steganography transcript of the IPv6 working group session). Some of you will probably know RIPE 554 as a quite helpful document for identifying reasonable real-world requirements for IPv6 capable network devices (in particular at times when vendors quite willingly put an “IPv6 ready” sticker on all their gear…).
Past month we (which is me and a group of other ERNW students, supported by some of the “old” guys — I hope my team lead won’t yell at me for this 😉 ) attended the Haxpo and Hack in the Box in Amsterdam. Starting from 28. May, we had three days at this great conference (HITB) and exposition (Haxpo). The two events took place in the former building of the stock exchange in Amsterdam, called: “Beurs van Berlage”. Upon entering the building for the first time we were given details on where our booth was and where the talks would take place — setting up our booth and planning the shifts was just another thing to do before exploring the Haxpo area:
From left to right: Sebastian, Burak and Heinrich at the ERNW booth
regularly we get requests from customers where the idea of using Skype as a VoIP solution in their corporate environment is brought up. There are a lot of eavesdropping and more conceptual concerns (e.g. refer to this or this, and of course the legendary “Silver Needle in the Skype” paper from Black Hat EU 2006), but those won’t be covered in this post (just to say this: at ERNW the use of Skype is strictly prohibited at by policy).
However, we worked on an interesting request that focused on Skype’s security impact on end devices, mainly concerning Windows clients. Skype has many features e.g. file sharing between users, the ability to set the port on which Skype listens, or clients becoming supernodes, which in turn can be relevant for the overall security impact on network or clients. The interesting part from a corporate perspective is the ability to configure those Skype settings via GPO, for which Skype even used to provide an ADM file. However, the settings in this file were quite outdated, which made us decide to put together a file for the settings of the most recent version of Skype. Relevant resources for this are the Skype IT Administrators Guide and a corresponding TechNet article on ADMX files (Managing Group Policy ADMX Files Step-by-Step Guide).
Our Skype ADMX files can be found here for download.
Besides the concerns of Skype usage in corporate environments in general (as mentioned above, this post does not discuss those), we want to outline some of the settings that can be relevant to protect clients and network:
Disable File Transfer: Disable file transfer to achieve that any user can’t send any internal data trough Skype.
Disable Contact Import: This setting prevents any user to import contacts trough the application itself, importing contacts can be realized over Skype-Manager tool.
Disable Web Status: If you disable this setting any user can’t publish their online status.
Disable API: Prevents usage of Skype API for third party applications.
Disable Version Check: This setting prevents Skype to perform an initially version check.
Memory Only: This setting makes it possible to run Skype without storing data on the local disk.
Listen Port: Skype normally listens on a default Port, this setting restricts the port to your settings.
Disable Supernode: This setting prevents a random user to become a supernode which makes it possible for this user to intercept traffic.
Proxy Type: HTTPS or SOCKS5. This also enables the use of the proxy in general
Proxy Address: “hostname:port” e.g. “socks5.mydomain.com:5050”.
Proxy Username: “username” e.g. “socks5user”.
Proxy Password: “password” e.g. “socks5pass”.
Despite our critical opinion on Skype, we hope that the files might help the secure operation of Skype in environments where it has to be used for some reasons.
Best,
Sebastian & Matthias
PS: We tested the files in our environment and did not experience any problems. We’re happy about bug reports, however it might take time to deploy changes and we cannot provide any support/warranty on the files.
As we continue our research in the 3GPP protocol world, there is a new tool for you to play with. It is called s1ap_enum and thats also what it does 😉
The tool itself is written in erlang, as i found no other free ASN.1 parser that is able to parse those fancy 3GPP protocol specs. It connects to an MME on sctp/36412 and tries to initiate a S1AP session by sending an S1SetupRequest PDU. To establish a S1AP session with an MME the right MCC and MNC are needed in the PLMNIdentity. The tool tries to guess the right MCC/MNC combinations. It comes with a preset of known MCC/MNC pairs from mcc-mnc.com, but can try all other combinations as well.
Last October I had a quick look at pfSense 2.1 regarding the IPv6 support that it offers. It was the first stable support of pfSense that offered the capability for IPv6 network connectivity (a few comments about it can be found here). However, I knew that m0n0wall supported IPv6 quite a long time ago and that their developers had incorporated the support of IPv6 features which are not available in pfSense yet, so today I decided to have a look at it too.
As it is well known to the IPv6 enthusiasts, one of the most significant changes that IPv6 brings with it, apart from supporting a really huge address space, is the improved support for Extensions and Options, which is achieved by the usage of IPv6 Extension headers. According to RFC 2460, “changes in the way IP header options are encoded allows for more efficient forwarding, less stringent limits on the length of options, and greater flexibility for introducing new options in the future.” So, by adding IPv6 Extension headers, according to the designers of the protocol, flexibility and efficiency in the IP layer is improved.
This can definitely be the case, but apart from it, it has already been shown that by abusing IPv6 Extension headers several security issues may arise (see for example my presentations at Black Hat Abu Dhabi 2012 and at the IPv6 Security Summit @ Troopers 13). This is why Enno Rey by talking straight to the point at the latest IPv6 Security Summit @ Troopers 14 described the IPv6 Extension headers as a “mess”!
I recently stumbled over a document from Microsoft which lists all services/applications that support IPv6. Most of the content wasn’t new for me, but one item caught my attention. Windows Update. I haven’t heard before that Windows Update can be done over IPv6 (but this could just be me not looking hard enough ;)), so I was eager to test it out seeing if this is really the case. I was also curious why Microsoft referenced this document in the respective column. Continue reading “Microsoft Windows Update over IPv6 (or not?)”
In the course of a recent penetration test, we came across an Image validation vulnerability in Django when using the Python-Imaging-Library (PIL) which we want to explain in this post.
Everybody who doesn’t know what Django and/or the PIL is:
Django is a framework to create web applications with Python (comparable to Rails or Zend). The PIL is a powerful standard python library which provides a toolset to modify, display and verify images of many different formats.
Applications that support the upload of images and validate the file type of those images using the PIL contain an interesting attack vector. For this attack vector, the most interesting image formats are X Bitmap (xbm) and the similar X PixMap (xpm). These two types are text based image files, which contain code to create a monochrome (xbm) or 256 color (xpm) image. In a web server system, these files can be abused to put content (eg. Python/PHP/Code or HTML files) on the server, as long as they pass the image validation process.
This results in the following possible exploitation scenario:
Every system with a Django-Server and PHP-enabled webserver sharing the same document root folder is a possible target for the described, as long as the storage paths for uploaded content are known, accessible and the content and extension of the uploaded files remain untouched (e.g.: no conversion takes place). Those paths can often be guessed as there are several default options.
Uploading python code is also an option, but may only be exploitable in case it is possible to upload to the main folder of the django application (to add malicious functionality). This scenario also requires wide knowledge about the used application, since it is required to find a way to make the application call the code in the uploaded source-files. In addition to this, Django has a very strict policy that forces the administrator to manually add any application to the Django-Server configuration. Even if the upload of a new django app succeeds, it will not be executed by the server, because it is not added to the configuration file yet. For this example, we thus resorted to the scenario with a PHP-enabled server.
To illustrate this scenario, I’m using the django-avatar app on an Xubuntu machine. First of all, a minimal configuration of django-avatar and apache was set up, running in the same document root folder, enabling us to upload avatars for a specific user using the avatar application.
Notice the following default values of django-avatar that enable us to actually exploit this scenario:
Hashing for filenames and userdirnames is disabled by default which makes it easy to determine the path where uploaded content is stored. But even if these options are enabled, it is still possible to access the file- and username directory by just using the corresponding MD5 hashes (no salt is applied).
The most important setting is ALLOWED_FILE_EXTS, which allows every PIL validated image to be uploaded when set to None. Setting this parameter to comma separated strings will lead to exclusively accepting the given extensions [e.g. (“jpg”, “gif”,) leads to only accepting “.jpg” and “.gif ”-files].
To start the exploitation and upload an actual image, we have to login and then browse to the /avatar/add sub-URL, showing the following website:
It is a simple upload page which allows setting avatars. The avatar is not being displayed, since it is not set yet.
We are now uploading a simple xbm file (script.php) with the following content:
Lines starting with a # are comments in xbm definitions. The part after line 3 is the Javascript to empty the page and the PHP-payload, which we use to execute arbitrary PHP code on the server. The actual image is not defined, but PIL will still recognize this file as a valid image, since it contains all the relevant syntax for a valid xbm image and ends with a ;. What comes after line 3 is just ignored by the PIL parser, since it is irrelevant to the image. So the PIL will verify the image and will allow the app to save the image in the avatar directory, where an additional resized version of the image is being generated and saved. The original file will be stored in the directory without any changes to filename, extension and content (except for a hashed filename, if enabled).
After uploading the file, a new avatar is created for the user which appears on disk and in the django admin panel:
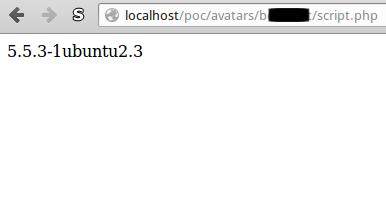
Given the apache server is running in the same directory, we now have our own php file on the server and can access all php functions. In our PoC we see the cleaned website with the additional PHP-Version information:
This process can be further exploited, since django-avatar will not overwrite files (instead create a renamed version of the same file: test.jpg and test_1.jpg) and stores old avatars when operating in default settings. Instead of uploading a harmless script to display the server version it is possible to upload a full php webshell and then further exploit the underlying webserver.
The django developers explicitly warn (see “Where should this code live?”) administrators to not run a classic server system (e.g. Apache) in the same directory as the django-server, meaning the overall chance of exploitation is low. Additionally exploitation is only possible if files are stored with their original extension, since the PHP-server will interpret the files depending on their file extension.
Even though this is not a vulnerability in the Django framework (it actually is a kind of a specific scenario), we still need to put more attention to this possible design pitfall, when using powerful libraries like the PIL. We further recommend the following best practices when developing Django applications or any upload-enabled web applications:
• Restrict (image-)file formats
• Do not store the original file on the disk, but instead convert every file to a specific format and only store the converted files.
• Delete unused data
• Set default values as safe as possible (people are lazy and tend to leave things that run untouched)
With this said: Happy coding and until next time! 🙂
This is the third – and hence presumably last – part of the series of posts on IPv6 address planning (first part can be found here, second one here). It’s split into three main pieces. In the beginning I will lay out some general objectives to be considered when designing an address plan. Then I’ll have a look at potential hierarchy levels and finally I’ll discuss some real-life samples we’ve seen recently.
On Saturday, April 26 Microsoft announced that Internet Explorer version 6 until version 11 is under potential risk against drive-by attacks from malicious websites, regardless of the underlying Microsoft operating system and the associated memory protection features integrated with the operating system. Microsoft has assigned CVE-2014-1776 to this unknown use-after-free vulnerability, which in the worst case could allow remote code execution if a user views a specially crafted website. If an attacker successfully exploits this vulnerability, s/he will gain the same rights and privileges as the current user (once again, activated User Account Control [UAC] helps keeping privileges of the user low).
The recommended mitigating controls from Microsoft, especially unregistering the VGX.DLL library has led to the misunderstanding, that many people thought the vulnerability is located in the VGX.DLL library. That is wrong. Instead, the vulnerability is located in mshtml.dll, mshtml.tlb, Microsoft-windows-ie-htmlrendering.ptxml, and Wow64_microsoft-windows-ie-htmlrendering.ptxml and therefore unregistering of the above library does not globally mitigate the vulnerability. It only mitigates a specific attack vector where Vector Markup Language (VML) is being used during the attack. Continue reading “The Role of VGX.DLL in the Context of the Latest IE 0-Day”