today we welcomed Michael Ossmann at the ERNW headquarter for an exclusive workshop on his HackRF gadget. Everybody was quite excited to get hands-on with this shiny piece of hardware, which is currently crowd-funded on Kickstarter. For everybody who’s not familiar with Software Defined Radio (SDR): Let’s regard it as the ultimate tool when working with radio signals.
Michael Ossmann in the house.
Let’s quote Michael’s campaign website:
Transmit or receive any radio signal from 30 MHz to 6000 MHz on USB power with HackRF. HackRF is an open source hardware project to build a Software Defined Radio (SDR) peripheral.
SDR is the application of Digital Signal Processing to radio waveforms. It is similar to the software-based digital audio techniques that became popular a couple of decades ago. Just as a sound card in a computer digitizes audio waveforms, a software radio peripheral digitizes radio waveforms. It’s like a very fast sound card with the speaker and microphone replaced by an antenna. A single software radio platform can be used to implement virtually any wireless technology (Bluetooth, ZigBee, cellular technologies, FM radio, etc.).
With HTML 5 the current web development moves from server side generated content and layout to client side generated. Most of the so called HTML5 powered websites use JavaScript and CSS for generating beautiful looking and responsive user experiences. This ultimately leads to the point were developers want to include or request third-party resources. Unfortunately all current browsers prevent scripts to request external resources through a security feature called the Same-Origin-Policy. This policy specifies that client side code could only request resources from the domain being executed from. This means that a script from example.com can not load a resource from google.com via AJAX(XHR/XmlHttpRequest).
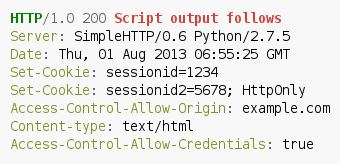
As a consequence, the W3 consortium extended the specification that a set of special headers allows access from a cross domain via AJAX, the so called Cross-Origin Resource Sharing (CORS). These headers belong to the Access-Control-Allow-* header group. A simple example of a server response allowing to access the resource data.xml from the example.com domain is shown below:
The most important header for CORS is the Access-Control-Allow-Origin header. It specifies from which domains access to the requested resource is allowed (in the previous example only scripts from the example.com domain could access the resource). If the script was executed from another domain, the browser raises a security exception and drops the response from the server; otherwise JavaScript routines could read the response body as usual. In both cases the request was sent and reached the server. Consequently, server side actions are taking place in both situations.
To prevent this behavior, the specification includes an additional step. Before sending the actual request, a browser has to send an OPTIONS request to the resource (so called preflight request). If the browser detects (from the response of the preflight) that the actual request would conflict with the policy, the security exception is raised immediately and the original request never gets transmitted.
Additionally the OPTIONS response could include a second important header for CORS: Access-Control-Allow-Credentials.
This header allows the browser to sent authentication/identification data with the desired request (HTTP-Authentication or cookies). And the best: this works also with HTTP-Only flags :).
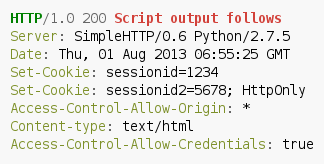
As you may notice, the whole security is located in the Access-Control-Allow-Origin header, which specifies from which domains client side code is allowed to access the resource’s content. The whole problem arises when developers either due to laziness or simply due to unawareness) set a wildcard value:
This value allows all client side scripts to get the content of the resource (in combination with Access-Control-Allow-Credentials also to restricted resources).
That’s where I decided to create a simple proof of concept tool that turns the victim browser into a proxy for CORS enabled sites. The tool uses two parts. First, the server.py which is used as an administrative console for the attacker to his victims. Second, the jstunnel.js which contains the client side code for connecting to the attacker’s server and for turning the browser into a proxy.
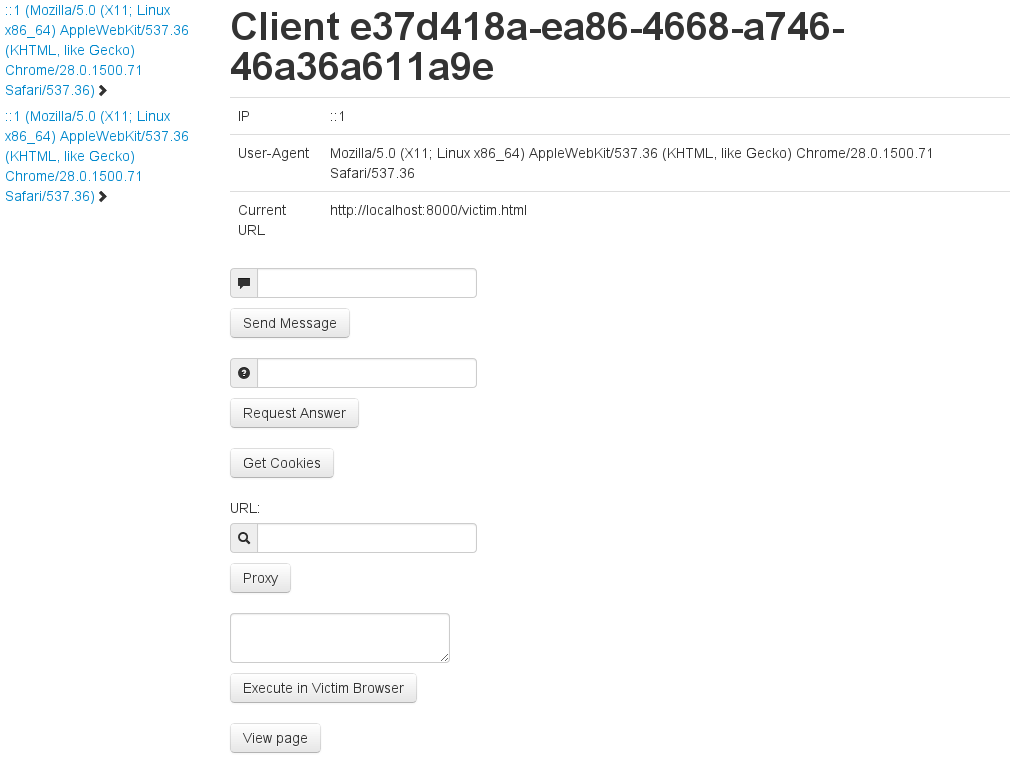
After starting the server.py you could access the administrative console via http://localhost:8888. If no victims are connected you will see an almost empty page. Immediately after a victim executes the jstunnel.js file (maybe through a existing XSS vulnerability or because he is visiting a website controlled by you…) he will be displayed in a list on the left side. If you select a connected victim in the list, several options become available in the middle of the page:
Some information about the victim
Create an alert popup
Create a prompt
Try to get the cookies of the client from the site where the jstunnel.js gets executed
Use the victim as a proxy
Execute JS in the victims browser
View the current visible page (like screenshot, but it is rendered in your browser)
If you select the proxy option and specify a URL to proxy to, an additional port on the control server will be opened. From now on, all requests which you send to this port will be transferred to the victim and rerequested from his browser. The content of the response will be transferred back to the control server and displayed in your browser.
As an additional feature, all images being accessible by JavaScript, will be encoded in base64 and also transferred.
You will find a vulnerable server in the test directory
This kind of functionality is also implemented in the Browser Exploitation Framework (BeEF), but I liked to have some lightweight and simple proof of concept to demonstrate the issue.
I’m currently catching up on a lot of papers and presentation from the Usenix Security Symposium in order to finish the blog post series I started last week (summarizing WOOT and LEET). One presentation, which unfortunately is not available online [edit: see also update, videos are available now], included several particularly relevant messages that I want to share in this dedicated post. Chris Evans, the head of the Google Chrome security team (herein short: GCST), described some new approaches they employed for their security team operations, some lessons learned, and how others can benefit from it as well (actually the potential of these messages to make the world a safer place was my motivation to write this post, even though I got teased for supposedly being a Google fanboy 😉 ):
Fix it yourself
The efficient security work carried out by the GCST could not be achieved if not all members of the team would also have a background as software developer/engineer/architect or in operations. This changes the character of the GCST work from “consulting” to “engineering” and enables the team to commit actual code changes instead of just consulting the developers on how to fix open issues (refer also to the next item). For the consultant work I do (and for assessment anyways 😉 ), I also follow this approach: When facing a certain problem set, have a look at the technological basics. Reading {code|ACLs|the stack|packets} helps in most cases to get a better understanding of the big picture as well.
Remove the middle man
The Google security work is carried out in a very straight way: All interaction is performed directly in a (publicly accessible, see later items) bug tracking system. This reduces management overhead and ensures direct interaction with the community as well. The associated process is very streamlined: Each reported bug is assigned to a member of the GCST which is then responsible for fixing it ASAP.
Be transparent
The bug tracking system is used for externally reported bugs as well as for internally discovered ones. This ensures a high level of transparency of Google’s security work and increases the level of trust users put into Chrome (transparency is also an important factor in the trust model we use). In addition, the practice of keeping found vulnerabilities secret and patching silently should be outdated anyways…
Go the extra mile
The subtext of this item basically was “live your marketing statements”. As ERNW is a highly spirit-driven environment, we can fully emphasize this point. Without our spirit (a big thx to the whole team at this point!), the “extra mile” (or push-up, pound, exploit, poc, …) would not be possible. Yet, this spirit must be supported and lived by the whole company: starting at the management level that supports and approves this spirit, down to every single employee who loves her/his profession (and can truly believe in making the world a safe place). As for Google, Chris described a rather impressive war story on how they combined some very sophisticated details of a PoC youtube video of a Chrome exploit without further details in order to find the relevant bug. (Nice quote in that context: “Release the Tavis” 😉 )
Celebrate the community
… and don’t sue them 😉 I don’t think there’s much to say on this item as you apparently are a reader of this blog. However, you have now an official resource when it comes to discussions whether you can disclose certain details about a security topic.
I think the messages listed above are worth to be incorporated in daily security management and operations and there is even some proof that they apparently worked for Google and hence may also improve your work.
Have a good one,
Matthias
Quick Update: All videos, including this talk, are now available.
This is the first part of an article that will give an overview of known vulnerabilities and potential attack vectors against commonly used Virtual Private Network (VPN) protocols and technologies. This post will cover vulnerabilities and mitigation controls of the Point-to-Point Tunneling Protocol (PPTP) and IPsec. The second post will cover SSL-based VPNs like OpenVPN and the Secure Socket Tunneling Protocol (SSTP). As surveillance of Internet communications has become an important issue, besides the traditional goals of information security, typically referred as confidentiality, integrity and authenticity, another security goal has become explicitly desirable: Perfect Forward Secrecy (PFS). PFS may be achieved if the initial session-key agreement generates unique keys for each session. This ensures that even if the private key would be compromised, older sessions (that one may have captured) can’t be decrypted. The concept of PFS will be covered in the second post. Continue reading “Vulnerabilities & attack vectors of VPNs (Pt 1)”
SUSE Linux Enterprise Server (SLES) has been around since 2000. As it is designed to be used in an enterprise environment the security of these systems must be kept at a high level. SLES implements a lot of basic security measures that are common in most Linux systems, but are these enough to protect your business? We think that with a little effort you can raise the security of your SLES installation a lot.
We have compiled the most relevant security settings in a SLES 11 hardening guide for you. The guide is supposed to provide a solid base of hardening measures. It includes configuration examples and all necessary commands for each measure. We have split the measures into three categories: Authentication, System Security and Network Security. These are the relevant parts to look for when hardening a system. The hardening guide also includes lists of default services that will help to decide which services to turn off, which is an essential step to minimize the attack surface of your system.
Truncating TLS Connections to Violate Beliefs in Web Applications Ben Smyth and Alfredo Pironti, INRIA Paris-Rocquencourt
This presentation was also given at BlackHat some weeks ago. It outlines a very interesting class of attacks against web applications abusing the TLS specification which states that “failure to properly close a connection no longer requires that a session not be resumed […] to conform with widespread implementation practice”. This characteristic enables new attack vectors on shared systems where certain outgoing (TLS encrypted) packets can be dropped in order to prevent applications from e.g. correctly finishing transaction (such as log out procedures) or even modifying the request bodies by dropping the last parts.
I have the pleasure to visit this year’s USENIX Security Symposium in Washington, DC. Besides the nice venue close to the national mall, there are also several co-located workshops. Every night I will try and provide a summary of those presentations I regard as most interesting. However, I hope to manage to keep up with it as there are a lot of interesting events, people to meet, and still some projects to keep up with. The short summaries below are from the 6th USENIX Workshop on Large-Scale Exploits and Emergent Threats.
A recent post describing some nasty vulnerabilities in HP multifunction devices (MFDs) brings back memories of a presentation Micele and I gave at Troopers11 on MFD security. The published vulnerabilities are highly relevant (such as unauthenticated retrieval of administrative credentials) and reminded me of some of the basic recommendations we gave. MFD vulnerabilities are regularly discovered, and it is often basic stuff such as hardcoded $SECRET_INFORMATION (don’t get me wrong here, I fully appreciate the quality of the published research, but it is just surprising — let’s go with this attribute 😉 — that those types of vulnerabilities still occur that often). Yet many environments do not patch their MFDs or implement other controls. As it is not an option to not use MFDs (they are already present in pretty much every environment, and the vast majority of vendors periodically suffer from vulnerabilities), let’s recall some of our recommendations as those would have mitigated the risk resulting from the published vulnerability:
Isolation & Filtering: Think about a dedicated MFD segment, where only ports required for printing are allowed incoming. I suppose 80/8080 would not have been in that list.
Patching: Yes, also MFDs need to be patched. Sounds trivial, yet it does not happen in many environments.
One recommendation we did not come up with initially are dedicated VIP MFDs, but this is something we have actually observed in the interim. As the MFDs process a good part of the information in your environment — hence also sensitive information — some environments have dedicated VIP MFDs, which are only used by/exposed to board members or the like. (As a side note, many MFDs also save all print jobs on the internal hard drive and do not retrieve them in a secure way. For example, we also mentioned in our presentation that the main MFD once used in our office kept copies of everything ever printed/scanned/faxed on it)
During one of our last projects in a large environment we encountered an interesting flaw. Although it was not possible to exploit it in this particular context, it’s worth to be mentioned here. The finding was about Cross-Site Request Forgery, a quite well-known attack that forces a user to execute unintended actions within the authenticated context of a web application. With a little help of social engineering (like sending a link via email, chat, embedded code in documents, etc…) an attacker may force the user to execute actions of the attacker’s choice. Continue reading “Cross-Site Request Forgery with Cross-Origin Resource Sharing”
That meeting was actually a great event. Once more, big thanks! to Fernando for organizing it and to EANTC for providing the logistics.
A couple of unordered notes to follow:
a) The slides of our contribution can be found here. Again, pls note that this is work in progress and we’re happy to receive any kind of feedback.
[given Fernando explicitly mentioned Troopers, we’ve allowed ourselves to put some reference to it into this version of the slide deck…]
b) the scripts Stefan currently puts together will be released here once they’ve undergone more testing ;-).
c) Sander Steffann mentioned that Juniper SRX models do have IPv6 support for management protocols. According to this link this seems somewhat correct.
d) we had that discussion about (which) ASA inspects work with IPv6. Here‘s a link providing some info for 8.4 software releases, this is the respective one for 9.0.
e) I was really impressed by the work performed by these guys and I think that ft6 (“Firewalltester for IPv6”) is a great contribution to the IPv6 security (testing) space.
And, of course, Marc’s latest additions to THC-IPV6 shouldn’t go unnoticed ;-). And I learned he can not only code, but cook as well.
===
Eric Vyncke commented “To be repeated”. We fully second that ;-).

{kind=link}