In this post, I will introduce fpicker. Fpicker is a Frida-based coverage-guided, mostly in-process, blackbox fuzzing suite. Its most significant feature is the AFL++ proxy mode which enables blackbox in-process fuzzing with AFL++ on platforms supported by Frida. In practice, this means that fpicker enables fuzzing binary-only targets with AFL++ on potentially any system that is supported by Frida. For example, it allows fuzzing a user-space application on the iOS operating system, such as the Bluetooth daemon bluetoothd – which was part of the original motivation to implement fpicker. Continue reading “fpicker: Fuzzing with Frida”
In the last blog post, we discussed how fuzzers determine the uniqueness of a crash. In this blog post, we discuss how we can manually triage a crash and determine the root cause. As an example, we use a heap-based buffer overflow I found in GNU readline 8.1 rc2, which has been fixed in the newest release. We use GDB and rr for time-travel debugging to determine the root cause of the bug.
This blogpost sheds some light on how fuzzers handle crash deduplication and what a unique crash is for a fuzzer. For this, we take a look at two contrived examples and compare the unique crashes identified by AFL++ and honggfuzz.
Last week I had the pleasure to attend Offensivecon 2019 in Berlin. The conference was organized very well, and I liked the familial atmosphere which allowed to meet lots of different people. Thanks to the organizers, speakers and everyone else involved for this conference! Andreas posted a one tweet tldr of the first day; fuzzing is still the way to go to find bugs, and mitigations make exploitation harder. Here are some short summaries of the talks I enjoyed.
I was at the hack.lu conference in Luxembourg this year and attended the fuzzing workshop, held by René Freingruber from SEC Consult. I have been curious about this topic for some years now, but besides doing some manual fuzzing and web-fuzzing, I never looked into the whole topic that much.
The workshop lasted for around four hours. Before the workshop started each student got two VMs (Linux/Windows) where everything necessary was already set up. The VMs included 23 exercises, with step-by-step explanations, source code and exploits. René started out with an introduction to fuzzing, listing popular fuzzers and showing an example on how to fuzz with afl.
Thereafter he explained the whole process of file format fuzzing, in a clear and easily adoptable manner. Examples were shown for Linux and Windows. The differences and difficulties as for fuzzing on Windows were explained. It was also shown how to find exploitable vulnerabilities from the previously acquired crashes.
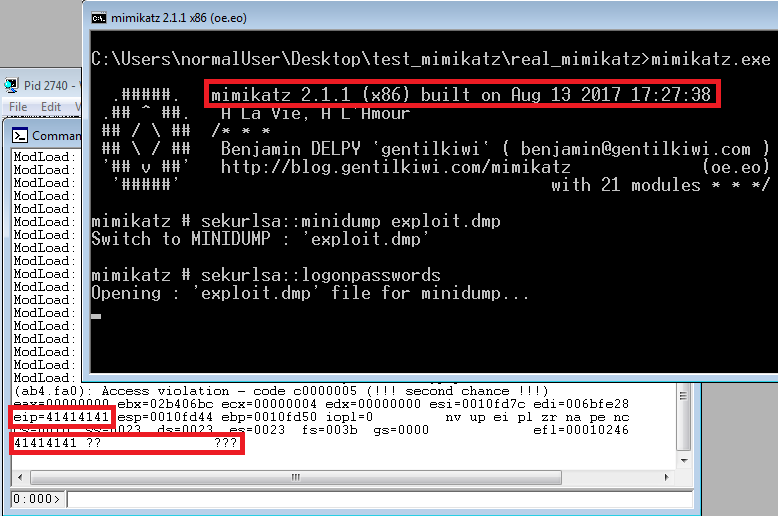
After a short break René introduced DynamRIO and PIN. Both tools are used for dynamic instrumentation. Two demos of the tools were shown, followed by a real-world example where he fuzzed mimikatz, the all beloved password recovery tool. To avoid running mimikatz on the compromised host, one can just dump the process memory of lsass.exe and load it into mimikatz to get credentials. Any idea where this is heading? Exactly, file format fuzzing!
Mimikatz EIP control
eip=41414141, looks like IP control to me ;D. A detailed writeup can be found over here.
The rest of the workshop René explained and discussed the areas which influence the fuzzing results. These can be divided into mutators, detection rate, input filesize and fuzzer speed. Instead of going into much detail myself I will just refer to his slides, which cover the topic way better than if I try to break it down in a few sentences.
René showed a lot of practical examples, although unfortunately there was not enough time to finish all of them while attending the workshop. Quite some time was spent on how to speed up the whole fuzzing process. Still I think it would be nice if more time could be spent on the practical examples.
The first exercise to introduce fuzzing and afl had the following source code. This code was then compiled with afl-gcc to add the instrumentation code with the following command: afl-gcc -o main_afl main.c
Additionally, input file(s) are needed, which in this case were created with the following command: python -c ‘print “\x00″*100’ > inputs/input
Then the fuzzer can be started with the following command: afl-fuzz -i inputs -o output — ./main_afl @@
The -i flag specifies a directory where the input files are located and the -o flag specifies a directory where the crash files should be stored. Now afl will run and fuzz the binary. For fuzzing a “real” (instrumented) binary, one would go through the following process:
Generate input files or download them.
Instrument the source code (if possible)
Remove input files with same functionality
Reduce file size of input files.
Start fuzzing
Removing the input files which trigger the same functionality is done before reducing their file size. One might guess, that this should be done the other way around, but reducing the file size can take a long time and should therefore be executed on the reduced file set.
To summarize the overall workshop:
I got a good understanding of the topic, what tools to use and how the process of fuzzing works.
The workshop could easily have been a three days workshop.
The students got awesome resources to start out their fuzzing journey, the slides are very good as are the VMs/demos.
So, I finally started to fuzz some binaries and have great fun doing so! Thanks very much for the workshop, René.
Fuzzing is a very old technique to find bugs and vulnerabilities in software. However it has seen a new push in recent years due to vastly improved tools. The compilers gcc and clang have received Sanitizer tools that allow finding a lot of bugs like use after free errors and out of bounds reads that are otherwise very hard to find.
and thanks for a great time at HES14! A nice venue (a museum), sweet talks and stacks of spirit carried us through the three day con. It all set off with a keynote byTROOPERs veteran Edmond ‘bigezy’ Rogers, who stuck to a quite simple principle: “People do stupid things” and I guess every single one of you has quite a few examples for that on offer. Next to every speaker referenced that statement at some point during her/his talk. Furthermore we presented an updated version of our talk LTE vs. Darwin, covering our research of security in LTE networks and potential upcoming problems.
For those who missed HES2014, we prepared a short summary of some of the talks that inspired us.
Within the last months I had some time to work on my code and today I’m releasing some of that: a new version of dizzy as well as two new loki modules.