Welcome back, Dear Reader,
in this post I’d like to share some reflections on the (potentially inefficient) way some security controls can be observed to be deployed in complex organisations and what this may mean for the future of those controls.
In general the space of security controls can be categorized according to different schemes, such as:
- By fundamental principle (preventive, detective, reactive, corrective, deterrent, compensating etc. security controls. see for example this overview or this one or some illustration here).
- By “state of matter” (e.g. components, implementation, operations. again, for some supplemental information look at this one).
- By type of admission: whitelisting vs. blacklisting (some general discussion here, the respective Schneier-Ranum Face-Off to be found here, and this is only Bruce’s half, but with a number of comments).
- Related to the overall architecture of implementation: centralized vs. distributed.
For today’s topic I’ll just focus on the latter two and will introduce those shortly.
Whitelisting vs. Blacklisting
Whitelisting can roughly be broken down to a “Deny everything except for $SOMETHING” concept. Typical examples of whitelist based security controls are rule sets on Internet facing firewalls or (discretionary) file system permissions/ACLs. The main caveat here is that, for going with a whitelist security approach, usually one has to “positively identify [the] $SOMETHING”.
Blacklisting is about the idea of “Allow everything except for something”. Examples of blacklist based security controls include pretty much all signature based stuff (malicious code protection in various flavors, IPSs etc.) and here usually just identification of “bad stuff” is needed. Which in turn is not too hard for many people (ever encountered a situation where somebody could easily tell you what she doesn’t want but struggled explaining what was actually desired? pls note that, in most earnest sincerity, in that example I used the female personal pronoun just for “gendering” as we call it in German) and can also be done by automated systems (“derive signature from exploit”).
Btw, an interesting discussion candidate would be to look at those over-hyped gadgets called “web application firewalls” (WAFs): while seemingly “firewalls” and hence mentally associated with “they only let the good stuff pass” concept, from an operational perspective they usually just perform blacklisting (deny “‘ or ‘1’=’1” like stuff) in most environments (which is the very reason why they contribute so poorly to overall security in most environments).
In a whitelist security control world, to be able to “positively identify something” (which is then going to be allowed), in general one has to know
- something about the business function of the asset(s) to be protected.
- their interaction with other entities (network communication relationships, users etc.).
In short one has to possess “contextual information”. The less contextual information, the more difficult it might become to deploy whitelist based security in an efficient way (for the record: I use the ISO 9000:2005 definition of efficiency here, that goes like “efficiency: relationship between the result achieved and the resources used”). If, for example, you don’t know much about the servers to be protected by means of some firewall rules you’re just about to create, you either end up with rules containing “any” somewhere or you might have to spend significant energy on finding out the protocols & ports needed.
Centralized vs. Distributed Security Controls
In the context of security controls, “centralized” may mean one of the following:
- application of security controls on the infrastructure level, e.g. at network intersection points.
- control of distributed enforcement points by means of centralized, _uniform_ intelligence (like anti-malware stuff with central signature distribution or MS Group Policies).
The key point here being that the intelligence & control is centralized (whereas the enforcement itself might not be).
“Distributed” usually means that there’s limited centralized intelligence & control as for security enforcement (still, the management e.g. of rule sets can be centralized, but those would not be uniform). Quite often “distributed” security happens in some topological proximity to $ASSET as this is where contextual/control information is available.
To summarize with some examples: a choke point firewall between network zones is a centralized security control, an individually configured instance of iptables on a Linux server somewhere in the data center is a distributed one, and ACLs applied to the segment facing interface of routers connecting a segment of servers to a corporate backbone are somewhere in between.
The Dilemma
So far so good, but there’s some nasty dilemma. Pretty much all infosec people have a strong sympathy for whitelist based security, ideally as centralized as possible (“steer the corporate universe’s information security posture from the control tower, ubiquitously only allowing what’s needed, of course”).
Unfortunately, usually the (“centralized”) people defining security rules (the “corporate infosec departments”) are not the ones possessing the contextual information (which would be “the business”, which in turn – by its very nature – is distributed). Still, for a whitelist approach to security, contextual information is heavily needed. Otherwise you end up with the least common denominator (for example subnet-based firewall rules with “any” service. which, just to make this clear, can be a valid infrastructure security approach – I mean it’s certainly “better than nothing” – and hence fully ok once one realizes the inherent limitations and one accordingly adjusts expectations). This becomes even worse when the people defining security rules are not consistent with those actually implementing them (outsourcing…).
This means that most often, in the end of the day, one has to choose two out of three of these objectives:
- Rules should be as precise & granular as possible (ever heard of “least privilege”? ;-)).
- Intelligence & control to be performed as centralized as possible (it’s the infosec guys “who know the stuff”, isn’t it? and infrastructure is the layer where to implement security controls, right?).
- Security operations should strive for efficiency (I mean they have to as resources are always finite, regardless how many there actually might be).
Or, looked at it from a different perspective, to achieve a whitelist based security architecture with centralized intelligence & control, one of the following preconditions would have to be met:
- Centralized knowledge (“we know all the servers throughout the network and their business function“). Sounds very realistic, huh? OR
- Centralized governance (“we define the rules and everybody has to follow, regardless of their [business] context“). Even more realistic 😉 OR
- Homogeneity (“it’s the same stuff everywhere so we can apply the same rules”). This accurately describes your organization, right?
In case you’ve not checked/confirmed at least one of those (read: in pretty much all sufficiently large organizations…) you have to accept a trade-off! Call it “(finding) the right balance” if you like.
To illustrate this have a look at this simple quadrant:
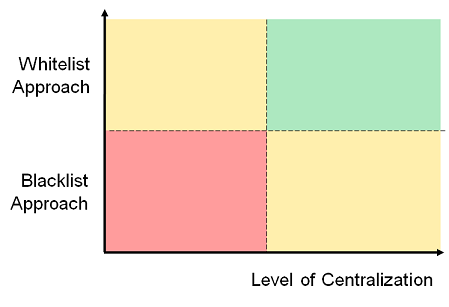
Realistically you have to position yourself and your organization’s infosec approach somewhere on that quadrant, while at the same time understanding that, the more you’re striving for the green, the more resources to put into the game OR the higher the efficiency (of the resources at hand) to be required.
The Moral of the Story
is twofold.
First and foremost be realistic about your goals & objectives! (remember the “choose two out of three” section above?)
Or, to put it bluntly, face the following facts:
- The higher the VUCA level of your organization, the smaller your chances for the green, as the gap between $ASSET_OWNERS (being able to provide context information) and $CONTROL_IMPLEMENTERS might be significant. Furthermore “contextual information” might change over time, but centralized security configuration usually does not. (Ever encountered a scenario where you had just configured some firewall rules and submitted them for the next CABs meeting when you received a flagged-as-urgent ticket telling you “that some services have to be added, due to re-configuration of main components”?).
- The more parties (read: potentially different ticket systems ;-)) involved, the smaller your chances for the green. (from a mere infosec perspective outsourcing of centralized sec controls rarely is a good idea, for the simple reason of giving up “contextual information”, which might have been present in security decisions within the organization before).
- The more cultural or terrestrial miles (or time zones) between $ASSET_OWNERS (being able to provide context information) and $CONTROL_IMPLEMENTERS, the smaller your chances for the green. (In physics they call this diffusion. Being a network guy, I call it attenuation ;-)).
- The more agile your business (think mobility & “the cloud”), the smaller your chances for the green.
So, in all those mentioned cases you might have to re-evaluate your expectations when it comes to whitelist-based, centralized security. Sorry for that, guys!
Second – and this was actually the starting ground I came from – when thinking about security controls in your next generation data center or corporate cloud, please fully understand the above difference between centralized and distributed security controls (it’s about where the intelligence & control sits! it’s not so much about management of rule sets.). I know that many people have high hopes with regard to “VM NIC Firewalls” (as networking & datacenter emperor Ivan called them in his excellent presentation on “Virtual Firewalls”, at Troopers13). Those won’t solve your current architecture’s problems when those problems are based on lack of contextual information/gaps between $ASSET_OWNERS and $CONTROL_IMPLEMENTERS. For example, Amazon EC2 Security Groups only work sufficiently well (governance wise) as it’s usually the asset (server instance) owners who apply them themselves (and subsequently there’s no such gap…).
I’m happy to receive your views, experiences, criticism or any other type of subject-related statement so feel free to leave a comment or contact me by PM. For the moment
take care & enjoy the summer sun
Enno