This is a write-up about how to use Frida to dump documents from a process after they have been loaded and decrypted. It’s a generic and very effective approach demonstrated on a piece of software from North Korea.
Python has reached a defacto standard in exploit development lifecycles and most of the proof of concept tools you’ll find out there are written in Python (besides the metasploit framework, which is written in Ruby). Python allows to write scripts handling with remote services, fiddling with binary data and interacting with C libraries (or Java in case of Jython/.Net in IronPython) in a fast and easy way. The huge standard library with it’s “battery included” principle removes some of the dependency hell known from other frameworks/languages. I want to share some of my python coding experiences with you, and maybe this could give some helpful tips for your future work, to make the world a bit safer 🙂 (PS: most of the examples are written in Python 3.x or compatible to both Python branches).
In the course of a recent penetration test, we came across an Image validation vulnerability in Django when using the Python-Imaging-Library (PIL) which we want to explain in this post.
Everybody who doesn’t know what Django and/or the PIL is:
Django is a framework to create web applications with Python (comparable to Rails or Zend). The PIL is a powerful standard python library which provides a toolset to modify, display and verify images of many different formats.
Applications that support the upload of images and validate the file type of those images using the PIL contain an interesting attack vector. For this attack vector, the most interesting image formats are X Bitmap (xbm) and the similar X PixMap (xpm). These two types are text based image files, which contain code to create a monochrome (xbm) or 256 color (xpm) image. In a web server system, these files can be abused to put content (eg. Python/PHP/Code or HTML files) on the server, as long as they pass the image validation process.
This results in the following possible exploitation scenario:
Every system with a Django-Server and PHP-enabled webserver sharing the same document root folder is a possible target for the described, as long as the storage paths for uploaded content are known, accessible and the content and extension of the uploaded files remain untouched (e.g.: no conversion takes place). Those paths can often be guessed as there are several default options.
Uploading python code is also an option, but may only be exploitable in case it is possible to upload to the main folder of the django application (to add malicious functionality). This scenario also requires wide knowledge about the used application, since it is required to find a way to make the application call the code in the uploaded source-files. In addition to this, Django has a very strict policy that forces the administrator to manually add any application to the Django-Server configuration. Even if the upload of a new django app succeeds, it will not be executed by the server, because it is not added to the configuration file yet. For this example, we thus resorted to the scenario with a PHP-enabled server.
To illustrate this scenario, I’m using the django-avatar app on an Xubuntu machine. First of all, a minimal configuration of django-avatar and apache was set up, running in the same document root folder, enabling us to upload avatars for a specific user using the avatar application.
Notice the following default values of django-avatar that enable us to actually exploit this scenario:
Hashing for filenames and userdirnames is disabled by default which makes it easy to determine the path where uploaded content is stored. But even if these options are enabled, it is still possible to access the file- and username directory by just using the corresponding MD5 hashes (no salt is applied).
The most important setting is ALLOWED_FILE_EXTS, which allows every PIL validated image to be uploaded when set to None. Setting this parameter to comma separated strings will lead to exclusively accepting the given extensions [e.g. (“jpg”, “gif”,) leads to only accepting “.jpg” and “.gif ”-files].
To start the exploitation and upload an actual image, we have to login and then browse to the /avatar/add sub-URL, showing the following website:
It is a simple upload page which allows setting avatars. The avatar is not being displayed, since it is not set yet.
We are now uploading a simple xbm file (script.php) with the following content:
Lines starting with a # are comments in xbm definitions. The part after line 3 is the Javascript to empty the page and the PHP-payload, which we use to execute arbitrary PHP code on the server. The actual image is not defined, but PIL will still recognize this file as a valid image, since it contains all the relevant syntax for a valid xbm image and ends with a ;. What comes after line 3 is just ignored by the PIL parser, since it is irrelevant to the image. So the PIL will verify the image and will allow the app to save the image in the avatar directory, where an additional resized version of the image is being generated and saved. The original file will be stored in the directory without any changes to filename, extension and content (except for a hashed filename, if enabled).
After uploading the file, a new avatar is created for the user which appears on disk and in the django admin panel:
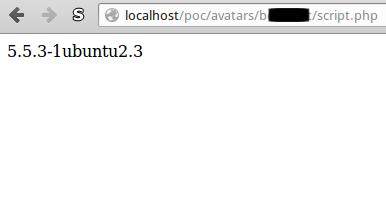
Given the apache server is running in the same directory, we now have our own php file on the server and can access all php functions. In our PoC we see the cleaned website with the additional PHP-Version information:
This process can be further exploited, since django-avatar will not overwrite files (instead create a renamed version of the same file: test.jpg and test_1.jpg) and stores old avatars when operating in default settings. Instead of uploading a harmless script to display the server version it is possible to upload a full php webshell and then further exploit the underlying webserver.
The django developers explicitly warn (see “Where should this code live?”) administrators to not run a classic server system (e.g. Apache) in the same directory as the django-server, meaning the overall chance of exploitation is low. Additionally exploitation is only possible if files are stored with their original extension, since the PHP-server will interpret the files depending on their file extension.
Even though this is not a vulnerability in the Django framework (it actually is a kind of a specific scenario), we still need to put more attention to this possible design pitfall, when using powerful libraries like the PIL. We further recommend the following best practices when developing Django applications or any upload-enabled web applications:
• Restrict (image-)file formats
• Do not store the original file on the disk, but instead convert every file to a specific format and only store the converted files.
• Delete unused data
• Set default values as safe as possible (people are lazy and tend to leave things that run untouched)
With this said: Happy coding and until next time! 🙂
With HTML 5 the current web development moves from server side generated content and layout to client side generated. Most of the so called HTML5 powered websites use JavaScript and CSS for generating beautiful looking and responsive user experiences. This ultimately leads to the point were developers want to include or request third-party resources. Unfortunately all current browsers prevent scripts to request external resources through a security feature called the Same-Origin-Policy. This policy specifies that client side code could only request resources from the domain being executed from. This means that a script from example.com can not load a resource from google.com via AJAX(XHR/XmlHttpRequest).
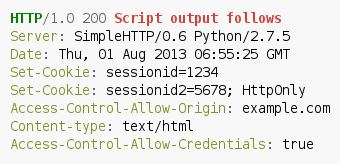
As a consequence, the W3 consortium extended the specification that a set of special headers allows access from a cross domain via AJAX, the so called Cross-Origin Resource Sharing (CORS). These headers belong to the Access-Control-Allow-* header group. A simple example of a server response allowing to access the resource data.xml from the example.com domain is shown below:
The most important header for CORS is the Access-Control-Allow-Origin header. It specifies from which domains access to the requested resource is allowed (in the previous example only scripts from the example.com domain could access the resource). If the script was executed from another domain, the browser raises a security exception and drops the response from the server; otherwise JavaScript routines could read the response body as usual. In both cases the request was sent and reached the server. Consequently, server side actions are taking place in both situations.
To prevent this behavior, the specification includes an additional step. Before sending the actual request, a browser has to send an OPTIONS request to the resource (so called preflight request). If the browser detects (from the response of the preflight) that the actual request would conflict with the policy, the security exception is raised immediately and the original request never gets transmitted.
Additionally the OPTIONS response could include a second important header for CORS: Access-Control-Allow-Credentials.
This header allows the browser to sent authentication/identification data with the desired request (HTTP-Authentication or cookies). And the best: this works also with HTTP-Only flags :).
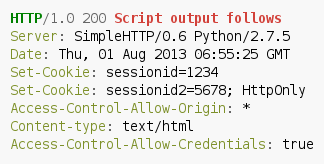
As you may notice, the whole security is located in the Access-Control-Allow-Origin header, which specifies from which domains client side code is allowed to access the resource’s content. The whole problem arises when developers either due to laziness or simply due to unawareness) set a wildcard value:
This value allows all client side scripts to get the content of the resource (in combination with Access-Control-Allow-Credentials also to restricted resources).
That’s where I decided to create a simple proof of concept tool that turns the victim browser into a proxy for CORS enabled sites. The tool uses two parts. First, the server.py which is used as an administrative console for the attacker to his victims. Second, the jstunnel.js which contains the client side code for connecting to the attacker’s server and for turning the browser into a proxy.
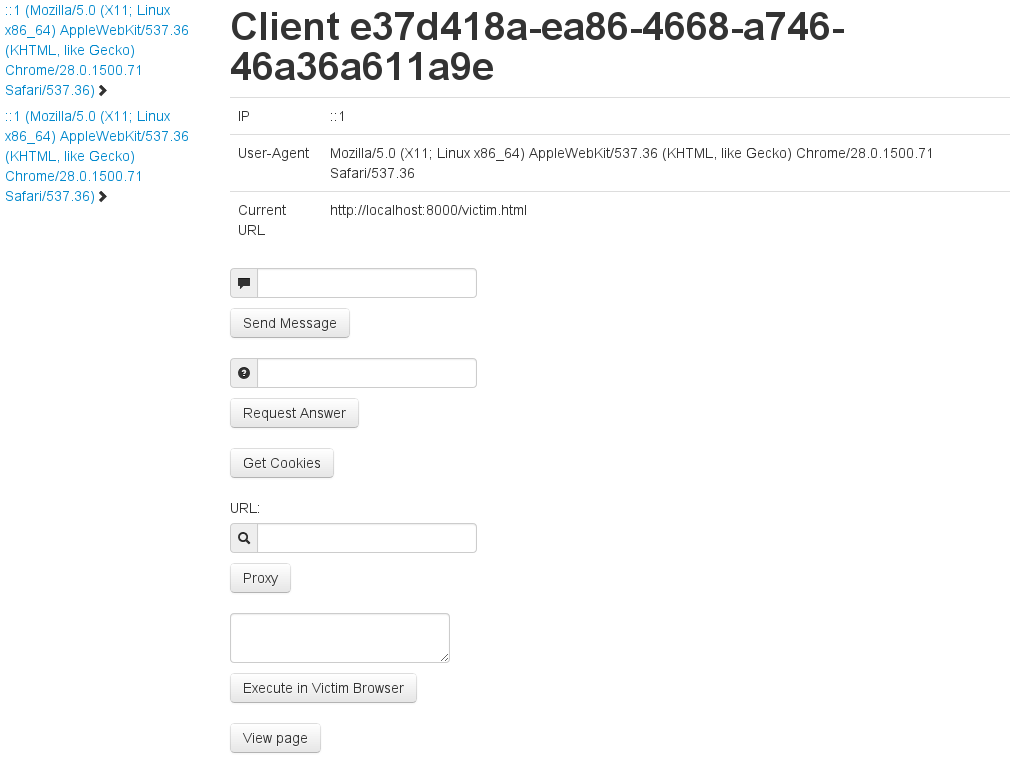
After starting the server.py you could access the administrative console via http://localhost:8888. If no victims are connected you will see an almost empty page. Immediately after a victim executes the jstunnel.js file (maybe through a existing XSS vulnerability or because he is visiting a website controlled by you…) he will be displayed in a list on the left side. If you select a connected victim in the list, several options become available in the middle of the page:
Some information about the victim
Create an alert popup
Create a prompt
Try to get the cookies of the client from the site where the jstunnel.js gets executed
Use the victim as a proxy
Execute JS in the victims browser
View the current visible page (like screenshot, but it is rendered in your browser)
If you select the proxy option and specify a URL to proxy to, an additional port on the control server will be opened. From now on, all requests which you send to this port will be transferred to the victim and rerequested from his browser. The content of the response will be transferred back to the control server and displayed in your browser.
As an additional feature, all images being accessible by JavaScript, will be encoded in base64 and also transferred.
You will find a vulnerable server in the test directory
This kind of functionality is also implemented in the Browser Exploitation Framework (BeEF), but I liked to have some lightweight and simple proof of concept to demonstrate the issue.
In a .NET environment WCF services can use the proprietary WCF binary XML protocol described here. Microsoft uses this protocol to save some time parsing the transmitted XML data. If you have to (pen-) test such services, it would be nice to read (and modify) the communication between (for example) clients and servers. One possibility is Fiddler.
Fiddler’s strengths include its extensibility and its WCF binary plugins. Sadly, these plugins can only decode and display the binary content as XML text.
Our first tool of choice for webapp pentests (Burp Suite) has also a plugin feature, and one can also find plugins for decoding (and encoding XML back to) WCF binary streams. But all WCF binary plugins out there are based on the .NET library which means one either has to work on MS Windows or with Mono. Another disadvantage is the validation and auto-correction feature of such libraries… not very useful for penetration testing 😉
That’s why we decided to write a small python library according to Microsoft’s Open Specification which enables us to decode and encode WCF binary streams. The library has a rudimentary commandline interface for converting XML to WCF binary and vice versa, as well as a plugin for our python-to-Burp plugin (pyBurp).
One of our favorite tools for conducting penetration tests (especially, but not only, web application tests) is Portswiggers’s Burp Suite. Burp allows to extend its features by writing own plugins. But because Burp is written in Java, it only supports Java classes as plugins. Additionally, Burp only allows to use one plugin at the same time which has to be loaded on start-up.
Now we have written a Burp-Python proxy (called pyBurp) which adds some features to the plugin system: