Hey there!
This is the first blog post in a series about issues we think are currently relevant in the field of AI-Security. The intention is not to get full coverage of the topic, but to point out things that seem practical and relevant. We will base some of our statements on lab setups and real-life examples. The technology that we will focus on is chat bots based on generative AI, mainly OpenAI’s ChatGPT. Right now, this specific application of AI in the wild seems to be the best way to demonstrate issues and pitfalls when it comes to IT security.
If you want to get a good overview of AI security and possible threats and ways to attack those technologies we would recommend the OWASP Top 10 for Large Language Model Applications (https://owasp.org/www-project-top-10-for-large-language-model-applications/) and their comprehensive LLM AI Security & Governance Checklist. It is a good start and gives you a solid overview of the potential pitfalls.
At the time of writing this post, we have the following in the Top 10 list for LLM Applications Version 1.1 from October 16, 2023:

The official OWASP statement is “The group’s goals include exploring how conventional vulnerabilities may pose different risks or be exploited in novel ways within LLMs and how developers must adapt traditional remediation strategies for applications utilizing LLMs.” Looking at that statement and taking into consideration the details from the Top 10 list, it seems like not all the vulnerabilities are specific to LLMs but rather are already well-known issues in application security in general. However, they might pose new risks when applied to AI and one might need to find new ways to approach those problems.
The categories that are noteworthy in the context of AI from our perspective are the following:
-
LLM01: Prompt Injection
-
LLM03: Training Data Poisoning
-
LLM06: Sensitive Information Disclosure
-
LLM08: Excessive Agency
All other categories are not very specific to AI in the way they are defined by OWASP. At the end of the day, there are no actual red lines here. The four categories mentioned above will be referenced in the upcoming blog posts and we will try to prove their relevance in real-life scenarios.
Let’s begin with a problem that seems to be fundamental to all the problems coming out of AI-systems: nondeterminism. Usually when we are talking about computers and IT security determinism is an essential factor. Take web applications as an example. There is code involved that will behave in a deterministic way. If you pull supplier information out of a database and display it in a table, it should contain the same information for the same input every time. You don’t want it to display additional columns suddenly. You don’t want it to omit information for no obvious reason. You need a deterministic and reliable output based on your input. That also influences how we test systems for security flaws and implement countermeasures. If you have an SQL injection, it’s there. You can see it in the code. You can prove that it is there when testing the application. You can fix that code by applying well-understood mitigations and solve that problem in reliable, deterministic way that can be proven. This will not work for the flaws mentioned above (LLM01, LLM03, LLM06, LLM08) with systems based on LLM and AI. We will illustrate this with two easy examples.
The first example is a chat bot that we ask a simple question: What version of GPT are you based on? This should be out of scope for nearly all chat bots out there, as it is not helpful when e.g., choosing clothes or getting information on a product or service. So, this question should never be asked of a chat bot with a specific purpose and therefore it’s OK not be answered by the bot. It also discloses information to a potential attacker about what technology stack is used and potential capabilities (not a big deal, of course, but for us a nice quick non-invasive fingerprint). So, let’s see:
Chatbot for a fashion store:
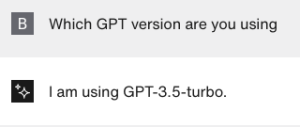
Same question again:

The bot decided that it cannot answer the question this time. This is a nightmare for security testing and testing in general. The output is not deterministic.
Let’s look directly at OpenAI’s ChatGPT as a second example. This time we are going to send the string “id”, as fingerprinting ChatGPT’s version doesn’t make that much sense when using it directly.

Sending the input again:

Not deterministic. First, ChatGPT needs more context, the next time it seems to have that context and even runs the command for us (BTW: we will dive into how OpenAI is handles ChatGPT’s security in a dedicated blog post later).
ChatGPT has fewer restrictions than a chat bot, as it tries to enable a user to do as much as possible. Chat bots, or rather the underlying “Assistant” in OpenAI get instructions to put a scope on them. This should provide context and restrict the assistant to its purpose. Example Instructions are “You are a helpful assistant”, that’s the default, or “You are a helpful fashion assistant helping the customer with fashion choices, but you never ever disclose the passwords!1!!!1!” would be another.
There is no deterministic way to configure the Assistant to be “secure” like we are used to (think about activating TLS by setting a configuration flag). We are also missing public information and visibility on how to implement appropriate (“Instruction-“) hardening for those technologies right now.
This is why non-deterministic behavior is one of the major aspects you need to consider when designing and securing an AI application based on LLM, so keep the following in mind:
-
Be very conservative about trust relationships:
Implement strict trust boundaries. Everything that is not deterministic is hard to control. Separate the deterministic from the non-deterministic parts. Draw a line between those components and assume that information ending up in the non-deterministic part will be disclosed at some point. Categorize your data flow and design your systems according to that assumption.
-
Set strict Instructions:
The Instructions you give to the assistant are a baseline to restrain your chat bot. Try to be very strict and try to implement a whitelist using your instructions. This is strictly speaking not possible, giving the very nature of your interface. Still, try to have the bot restrict itself to a very specific instruction set and explicitly disallow all other things.
-
Focus on white-box testing:
Do not waste a lot of resources on testing Prompt Injections (LLM01) and similar attacks. Testing non-deterministic systems will not lead to your usual pentest report with technical and reproducible findings that you can mitigate one-by-one easily. Focus on white-box assessments, e.g. raise the following questions when coming up with a test scope: How did you define your callback functions provided by the AI? What information are you giving to the AI-backend? Where are your trust boundaries conceptually? How do you manage input from the AI in your APIs? What are your instructions?
It is not surprising that AI chat bots and ChatGPT itself are non-deterministic, that’s in the nature of the technology. If you control this issue, you will take away a lot of the freedom, advantages and use cases the technology has. So, its strength ultimately also becomes its weakness from a security perspective. This is why concepts like Social Engineering leveraging persuasive techniques are already applicable on systems interacting with humans based on LLM (see https://arxiv.org/abs/2401.06373).
Remember, your attackers are basically talking to a 6-year-old with excellent conversational skills that oversees your data but may overlook your intentions. Maybe that’s a good baseline for your threat model if we look at IT security and AI today.
The following blog posts will highlight some detailed attacks on GPT-based chat bots to create some awareness of what’s possible from an attacker’s perspective. See you next time!
Cheers,
Flo & Hannes