I am Andrei Costin (at http://firmware.re project), and this is the first post from a series of guest postings courtesy of ERNW.
Between 24th and 28th October, I had the pleasure and the great opportunity to attend ACM CCS 2016 in Vienna, Austria, where I also presented at the TrustED’16 workshop my paper titled “Security of CCTV and Video Surveillance Systems: Threats, Vulnerabilities, Attacks, and Mitigations”.
My attendance throughout the entire ACM CCS 2016 week and my presentation at TrustED was possible thanks to generous support from Enno Rey and ERNW, and I thank them again for this opportunity!
In these guest postings I am going to summarize the talks I have attended, and will try to make you interested in exploring more on each of the mentioned papers. As a side note, the ACM CCS 2016 week was pretty intense, with 5 parallel tracks for the main conference and close to a dozen of pre- and post- conference workshops. Therefore, it is physically impossible to attend and summarize all the papers. But I give you a scoop of papers which I personally found interesting (or chose to attend when there was a clash between two interesting talks).
Without further ado, here come the summaries.
Stay secure.
Andrei.
CCS’16 – Day 1 – 24th October 2016
“SecuRank: Starving Permission-Hungry Apps Using Contextual Permission Analysis ”
Vincent F. Taylor presented SecuRank, which is a framework/tool (available both as a web-service and as an Android app) that identifies and suggests functionally-similar apps (to a given app), but which require less or minimum of “dangerous” permissions (e.g., camera access, microphone access).

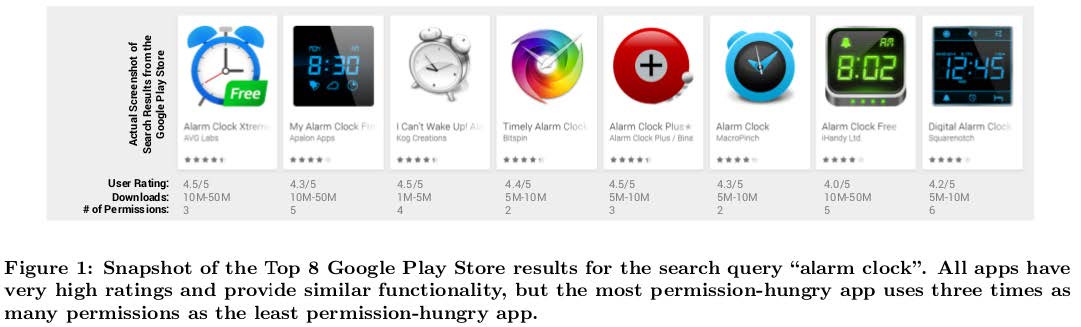
Their work is motivated by the fact that for general purpose apps (e.g., alarm clock, flashlight) the required permissions vary greatly among apps in the same functional group. For example, many times the top ranked apps do not necessarily mean “safer” apps in terms of require permissions-set. The permission-hungry apps could be explained by the fact that apps competition is fierce and all apps try to add distinguishing features, therefore adding more and more “dangerous” permissions. The goal of SecuRank work is to mine details and permissions of apps, and then try to suggest “safer” alternatives, but which provide the same or similar functionality.
Their methodology is straightforward. First, they collected full app details from around 1.7 mil apps in Google Play Store. Then, they generate popular search queries and use auto-suggestion APIs to find “similar” apps. Finally, a very important step – they ensure app similarity by using a proposed similarity measure, using app descriptions and choosing a grouping size of 20.
CONCLUSIONS:
First, from the entire Google Play Store, up to 50% of apps can be replaced with preferable (e.g., safer) alternatives. Unsurprisingly, the free apps and very popular apps more likely to have such alternatives.
Second, around 6% of the #1 ranked apps were found to use “rare” permissions. In SecuRank’s methodology, a “rare” permission is a permission that is used by only one (or a smallest minority of) app(s) in a given functional group (e.g., alarm clock), for example “camera access” permission for an alarm clock app.
LINKS:
https://play.google.com/store/apps/details?id=me.securank.jov
EXAMPLES:
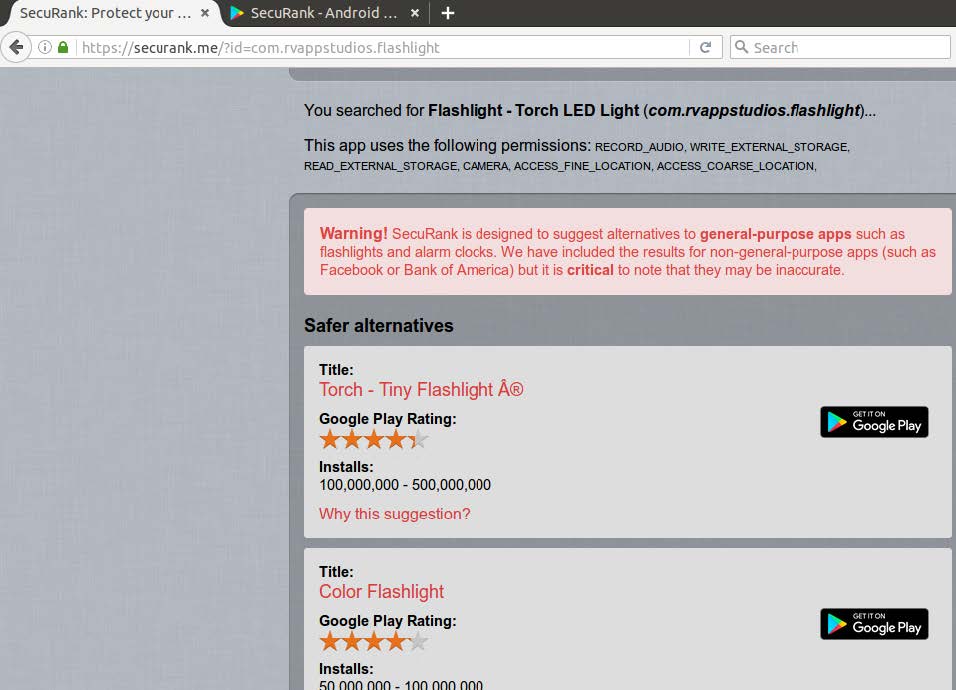
https://securank.me/?id=com.rvappstudios.flashlight
“Securing Recognizers for Rich Video Applications ”
Christopher Thompson presented the paper “Securing Recognizers for Rich Video Applications ”. Their work is motivated by the fact that granting applications full access to video data (e.g., Google Glass or camera access permission on Android device) exposes more information than is necessary to achieve their functionality. This in turn introduce (major) privacy risks.
They propose propose a privilege-separation architecture for visual recognizer applications (i.e. apps that require access to raw video stream and/or perform processing on the raw video stream for example for face recognition). Their proposal encourages modularization and the principle of “least privilege ”
separating the video recognizer logic, sandboxing it and restricting what it can extract from the raw video data.
Their prototype is implemented using Python, OpenCV, ZeroMQ (see LINKS for source code), and incurs insignificant overhead. All their experiments were performed on a Raspberry Pi 2 Model B (900MHz quad-core ARMv7 CPU, 1GB of RAM, Raspbian 7, headless mode under the virtual framebuffer Xvfb). Authors suggest this device is similar to Google Glass in terms of hardware and performance.
CONCLUSIONS:
The proposed privilege-separation architecture has many benefits. First, it helps secure video recognizer apps. Second, their approach is shown to be practical, adding low performance overhead, while keeping developer burden (to port/rewrite existing apps, or to develop new apps for the secured architecture) to a minimum. Third, it provides increased benefits in terms of security and privacy.
LINKS:
https://github.com/christhompson/recognizers-arch
“On a (Per)Mission: Building Privacy Into the App Marketplace ”
Hannah Quay-de la Vallee presented the paper “On a (Per)Mission: Building Privacy Into the App Marketplace ”.
The starting observation of this work is that apps marketplaces are ideally positioned to inform users about privacy aspects of each app, however they fail to take advantage of this. The motivation for this work is the lack of privacy guidance that makes it difficult for users to make informed privacy decisions. For example, there are general ratings (functional, etc.) for apps, but there are no “privacy” ratings for each app. One goal of this work is to incorporate privacy information as a key element, in the form of permission ratings for apps in the marketplace.
One key challenge was to properly represent the permission ratings, so that it makes sense to the whole/majority of users. For this, they used Amazon Mechanical Turk and several iterations over the “permission rating” UX design:

Finally, “percentage bars” were found to work the best in representing “permission ratings” in a privacy-aware marketplace:
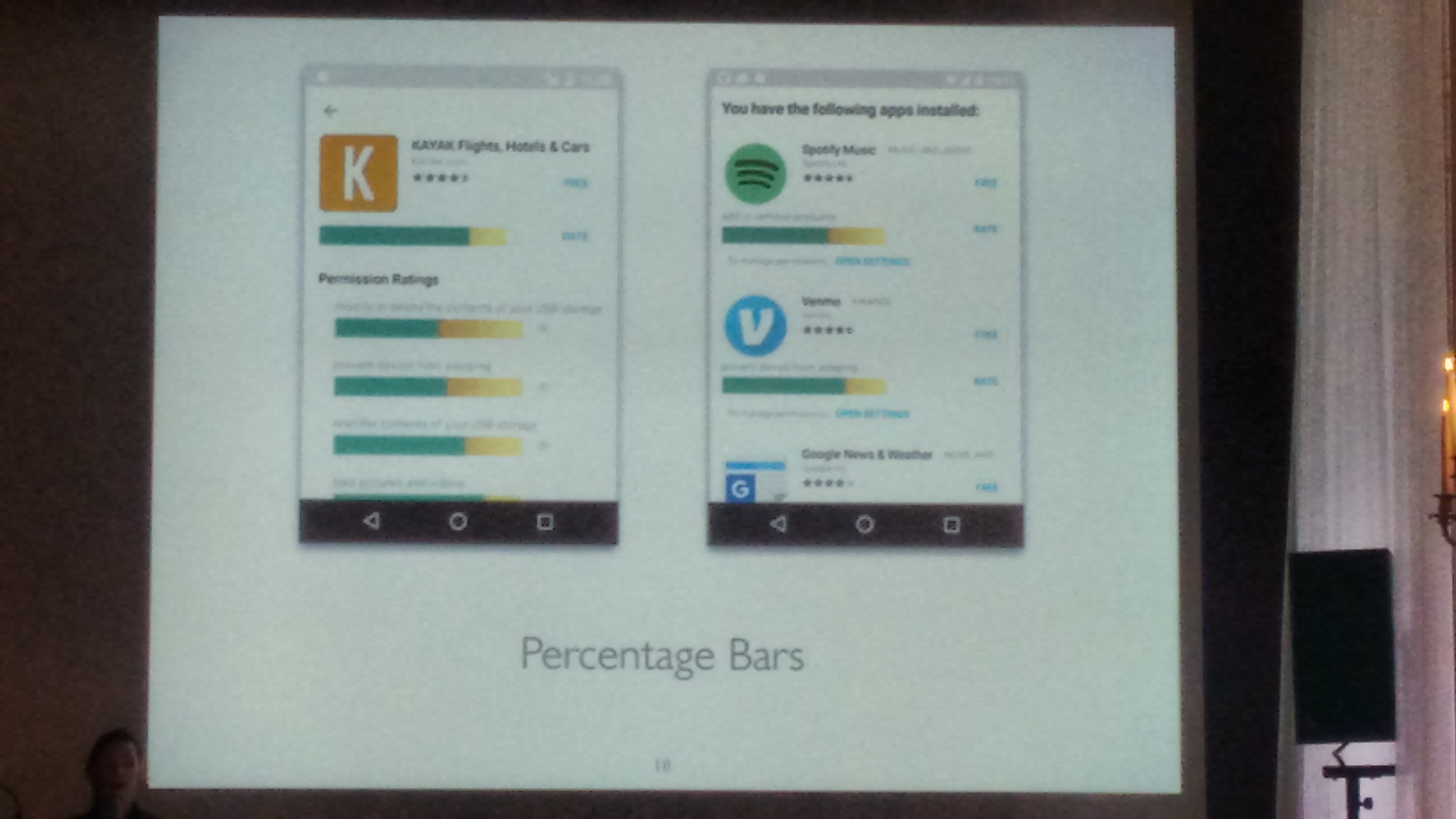
Their implementation provides a web-service and two Android apps (see LINKS for details). The “PerMission Store” helps you find apps that won’t invade your privacy. The “PerMission Assistant” helps you decide which permissions to turn off, and which to leave on.
LINKS:
https://play.google.com/store/apps/details?id=com.permission.store
https://play.google.com/store/apps/details?id=com.permission.assistant
“Exploiting Phone Numbers and Cross-Application Features in Targeted Mobile Attacks ”
Srishti Gupta presented the paper “Exploiting Phone Numbers and Cross-Application Features in Targeted Mobile Attacks ”.
Their research goal was to demonstrate the feasibility, automation and scalability of launching targeted attacks (targeted by phone numbers). In this work, such targeted attacks exploit cross-application features and phone numbers abuse enabled by those features. For example, such attacks are enabled by new Over-The-Top (OTT) messaging applications (e.g., WhatsApp, Viber, WeChat etc.) that emerged as an important/alternative means of communication. In a nutshell, their system architecture is as follows:
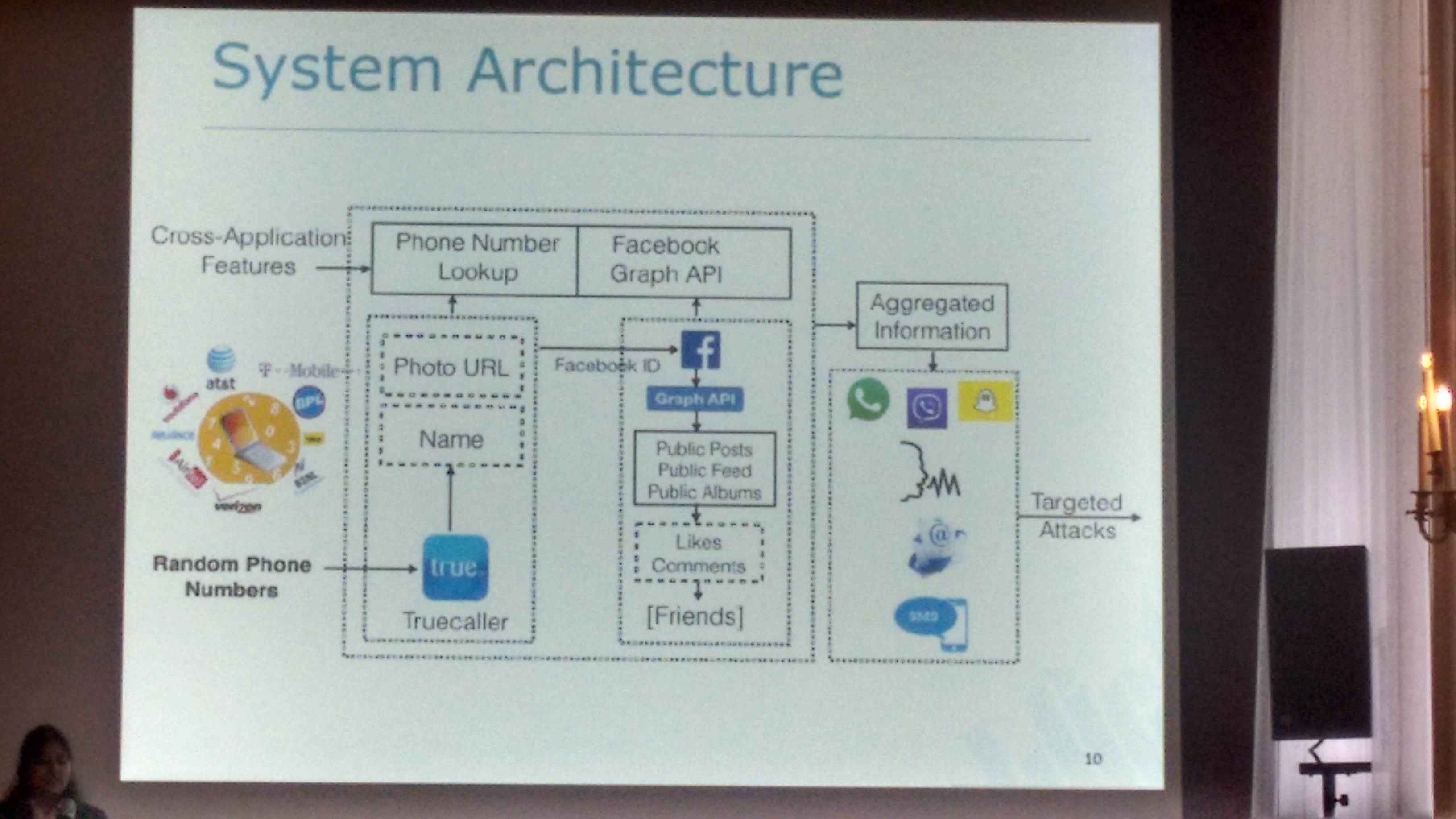
They bootstrap their data from TrueCaller APIs. They inserted into the phonebook a large number of random phone number, and then used TrueCaller on each number to pivot from there. In the experiment, they searched TrueCaller for 1,162,696 random Indian phone numbers and found personal information on 722,696 users (phone numbers?). The additional extracted information ranged from name, address, email, to photo URL, OSN handlers (Twitter and Facebook). Subsequently, the variations of classical mining techniques were applied to OSN (Facebook Graph API) and public data (feeds, posts, albums). They managed to mine Facebook data on 112,696 users, and for 93% of these extracted additional social circles data. For mining techniques, you can see “All your contacts are belong to us: automated identity theft attacks on social networks”.
It was quite surprising to see that it is still (!) harvest so much info, starting with random phone number in your phonebook (pretending you have them as contacts), without any kind of limitation, authentication or authorization checks. Previously, myself and some colleagues also looked at phone-numbers abuse/misuse/attacks in “The role of phone numbers in understanding cyber-crime schemes”
“Picasso: Lightweight Device Class Fingerprinting for Web Clients ”
Elie Bursztein presented the paper “Picasso: Lightweight Device Class Fingerprinting for Web Clients”.
The challenge they proposed to solve is something along the lines on how to distinguish an authentic iPhone running Safari on iOS from an emulator or desktop client spoofing the same configuration . Solving this challenge with high accuracy, and with minimal usability and performance overhead, allows to build higher primitives of trust, as depicted by Elie below:
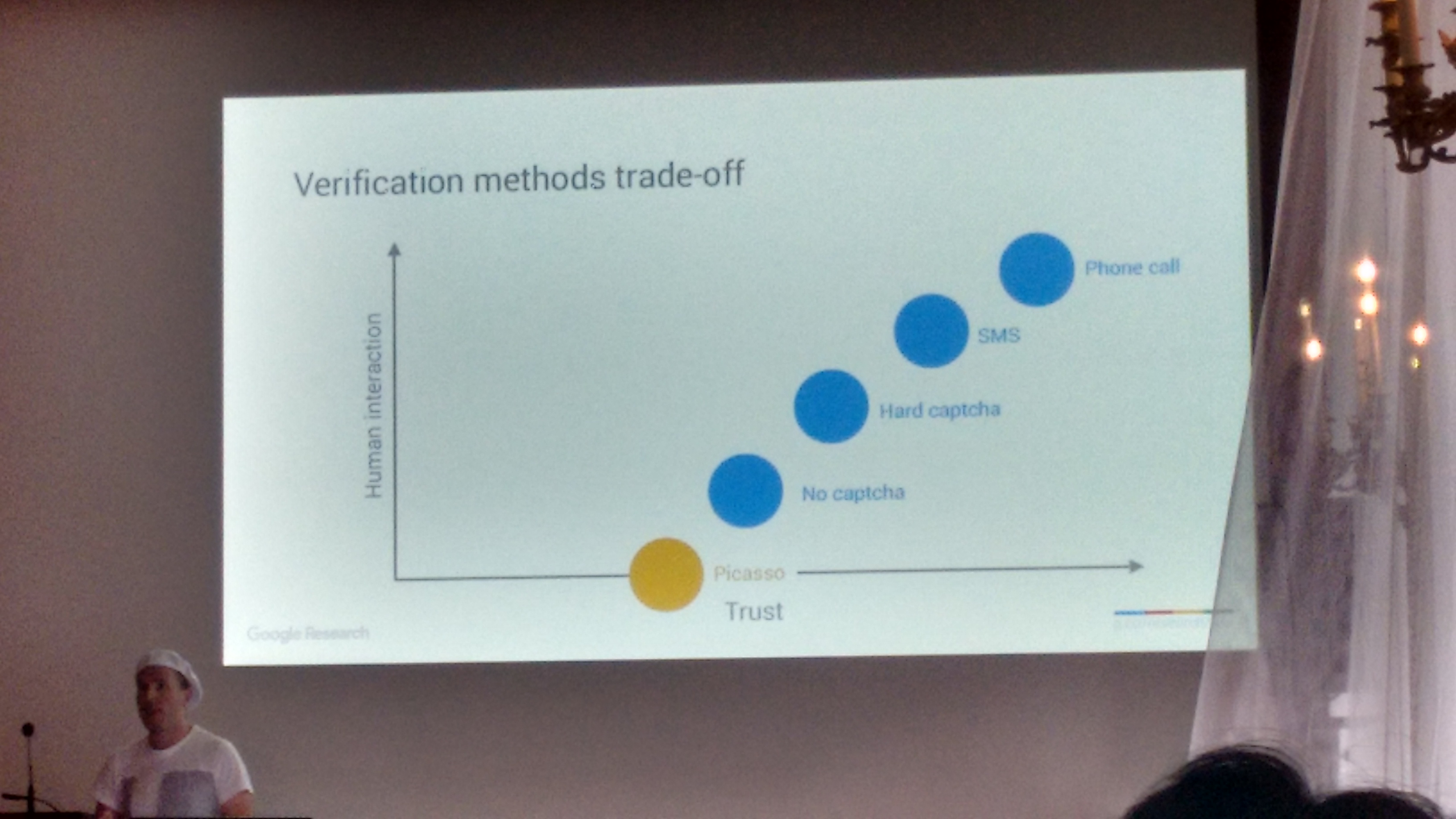
Basically, Picasso provides a relative trust that a given devices is what it claims to be (e.g., iPhone with iOS 7, running Safari), with a frictionless approach (i.e., zero human interaction).
The basic idea is as simple as nice – every given configuration (hardware, OS, application/libraries/graphic stacks) will have a “rendering fingerprint”. Even though those rendering artifacts are hardly distinguishable for human eye, they produce quite different renderings (i.e., different fingerprints) at the imaging level, as depicted below:

Picasso works as a “challenge” and “verify” technology, similar to reCAPTCHA (which seems to be one of the Elie’s main specialties)
Finally, for the privacy skeptics, as Elie explained, their goal is not to find out who you are at the person level. The assumption here is that they already know who you are, as for example you are already logged in. What they actually want to know (and do this as accurately and as frictionless as possible) is to know whether you are using the device/browser they expect you to use. By extension, this could potentially be used to detect unauthorized access to your accounts from account farms that try to emulate your (smartphone) device.
Their work is impressive at both scale and accuracy level. Their JavaScript implementation of Picasso, under certain configurations, is able to successfully distinguish the browser family (Chrome, Firefox, etc.) and the OS family (Windows, iOS, OSX, etc.) of over 52 million clients with 100% accuracy.