This is the third – and hence presumably last – part of the series of posts on IPv6 address planning (first part can be found here, second one here). It’s split into three main pieces. In the beginning I will lay out some general objectives to be considered when designing an address plan. Then I’ll have a look at potential hierarchy levels and finally I’ll discuss some real-life samples we’ve seen recently.
Related References
There are a number of documents out there already covering the subject. Given I might reference – in one way or another – those sometimes I will list them in the following. These are the three most important:
[SURFNET_ADD_PLAN]: RIPE/SURFnet document “Preparing an IPv6 Addressing-Plan” (Version 2, 18 September 2013).
[BCOP_IPv6_SUB]: NANOG Best Current Operational Practices – IPv6 Subnetting (v1, 18 October 2011).
[CISCO_WP]: Cisco IPv6 Addressing White Paper (old [2008?], but widely considered good introduction).
Beneficiaries & Objectives
Before we get into tackling the actual elements of the plan some (more ;-)) reflections have to take place. First you should keep in mind that the plan (or at least its kind-of outcome, read: the addresses themselves) will be used by many people. So when designing the plan carefully think of/about its beneficiaries. These can be (network) planners, operators, customers, service desk personnel or others. Whatever the outcome of your planning exercise might be, be aware that its value is probably not equal for all of them.
For example, incorporating a floor number in an address might help service desk people (I even doubt that) but will probably increase the need for renumbering once the next corp re-org takes place (read: in 18 months latest) so the admins in the field will not be happy about that. Designing a mathematically well thought-out and elegant scheme of prefix assignments throughout your global organization assumes that country organizations or plants receiving a prefix to further sub-divide on their own understand the scheme (designed in some ivory tower at $CORP_HQ_SITE) which then again might be the case, or not. Which is, btw, why I’m a bit skeptical as for the “Painting by numbers” approach shown at last year’s Heise IPv6 Kongress and to be presented in the IPv6 WG at RIPE 68 in Warsaw tomorrow. While (I think) I understand the underlying concept, which I have quite some sympathy for as it elegantly exploits certain properties of hex numbers and bit logic, I’m not sure if every network team lead of every plant will understand it (and hence follow the inherent logic).
Furthermore, and much more importantly, you MUST reflect on and clarify the objectives you’re pursuing while designing the plan. Those objectives can be developed along some guiding/underlying questions. These can include:
a) Does it (the plan) allow for or foster aggregation? [related property: “ability to aggregate”]
That’s the one many discussions (and recommendations) focus on, especially in provider space. While router TCAM memory usage by (internal) IPv6 routes is probably – hopefully – not your most critical concern there’s mainly two reasons why you should still strive for this:
– Simplicity! (yes, periodically re-reading RFC 3439 is a good idea…).
– Being a good (Internet) neighbor in case eventually some of your routing information will be propagated externally.
b) To what degree does it prevent renumbering? [ “ability to persist” or just “persistence”]
Given my personal background in large scale network operations and ERNW’s mantra “operations is key” you won’t be surprised that this is the one that I hold to be most important. This MUST be a guiding principle throughout the whole planning process. IPv6 and, with it, systems’ identifiers (read: their addresses) are going to stay with you/us for a long time. Any mistake you make in your plan due to not paying enough attention to this property will cost you dearly, in the long term.
Occasionally you’ll see plans which incorporate a “building” (in the physical sense) component, e.g. at the /60 boundary. Honestly, I do not see much value/benefit in that one. What do you gain from it, “significance”-wise (see next section)? On the other hand, ask yourself: how often do you think a given system’s location (building) will change within the next – say – 20 years? This might then either mean renumbering this system (which “still requires work”, see also RFCs 6879 and 7010) or loss of “significance”.
c) How much additional information does it provide (mainly) to humans? [let’s call this property “significance”. Initially I was in favor of terms along the lines of “entropy” (in the Shannon sense) but now prefer this term for it. [SURFNET_ADD_PLAN] calls it “legibility”.]
When designing an IPv6 addressing plan, for many people this is a quite important aspect. Indeed it might make perfect sense to convey various kinds of information in an address, so that a human looking at it could deduce: “looking at the address this system apparently belongs to a certain business unit/is located in a certain facility” or “this is apparently a database server” etc.
So this property is often considered an important one. BUT, please allow two remarks here:
First: don’t overload it! The whole “significance” approach only makes sense as long as a human can derive added value from it. Once you lose (e.g. due to organizational or topology changes) the clear correlation of address bits to information units the whole thing becomes useless. The higher the number of “information units” the higher the risk of loss of significance (or frequent renumbering to keep the relationship).
Second: quite a few people are tempted to include some mapping of IPv4 network (topology) information in (to) their IPv6 addresses. Now, what’s the significance (information content) of IPv4 network info in 10 years? See… that’s why you might do that. not.
d) To what degree does it support additional machine-based uses? [“applicability”]
This can be broken down to: “can we use certain elements/bits of the prefix for any type of machine-based processing (packet-handling), e.g. within ACLs for filtering or QoS?”.
Again, this seems like (and actually is) a reasonable goal at the first glance. On the other hand, again, do not overstress this one. Once you can’t keep the relationship consistent (and simple!) you’ll lose the benefit over time. There’s address plans/schemes with stuff like “the first half of this prefix, so with the nth bit set to 0, can be reached from external networks, and the other half, with nth bit = 1 is ‘internal’ and we can hence filter (it) at our perimeter accordingly”.
Easy, isn’t it? Now, what happens when, in 3 years, an application running on an “internal” system is to be made available to/from the Internet, to generate incredible revenue? You either move the application to another (“external”) system ($APP_OWNER will be excited about the prospect), renumber the system ($SYS_OWNER will be excited about the prospect) or “add a kind-of exception to the firewall rules”. We all know who’s gonna “win”, don’t we? Then, another 3 years later, after having “enabled” several dozens of such applications…
e) To what degree does it support growth? [“extensibility”]
This is somewhat related to “persistence”. I mean there’s enough addresses anyway, so you WILL not run out of addresses. You might lose a consistent scheme, routing aggregation, whatever, but you will not run out of addresses ;-).
f) To what degree does it allow for delegation of tasks? [“ability to delegate”]
This comes into play within organizations with a high degree of distributed IT operations. The more complex your scheme is (=> the more you have to explain it to plant network people so they can follow those smart guidelines you came up with) the higher the risk of heterogeneity and inconsistency at the “lower hierarchy levels” (prefix-wise).
All the above are potential objectives for your addressing plan and it helps to reflect on these first and prioritize them. Keep in mind that you will probably not be able to reach all these/such objectives to the same degree, with the same plan. Usually, for example, persistence (“avoid renumbering in long term”) and significance (“convey [as much] additional info for humans”) are somewhat exclusive.
Hierarchy Levels
The most important elements of an IPv6 addressing plan are the number and type of hierarchy levels which the prefixes (lengths) get assigned to. So let’s focus on those now.
Keeping nibble boundaries in mind and assuming a /32 as starting point, four hierarchy levels (/36, /40, /44, /48) are possible up to the /48 point and from there on, another four (/52, /56, /60, /64) up to the /64 point. So theoretically one could go with eight hierarchy levels, but – of course – you would never think about that, right? Just in the improbable case you’re tempted, go re-read RFC 3439.
The /48 boundary plays a main role in many schemes I’ve seen so far, for several reasons, both of a technical and psychological nature. First you can probably not expect that anything longer than /48 will be routed globally and in many networkers’ heads a /48 is what is typically assigned to a site. Furthermore in RIPE space a /48 is the expected default size for (PI or PA) assignments to “end users/sites” (at least this is a common interpretation of RIPE 589). In short: in most plans, /48 is considered an important prefix length (which is often assigned to a “site” or “location”).
From a high-level perspective there are two main classes of an address plan’s hierarchy levels: “topology-oriented” or “service-/function-oriented”.
Examples of topology-oriented categories, which then lead to prefix lengths, include (one must potentially differentiate between physical topology [e.g. countries] and network topology [e.g. VRFs]. These are not necessarily consistent, think for example of a VRF spanning multiple countries across an MPLS backbone):
o Region
o Country
o VRF
o Facility
o Site
o Location
o Building
o Floor
o VLAN
Examples of service/function-oriented categories include:
o “Clients” (wired, WLAN, VPN)
o Servers (in all flavors, like AD, DB, Citrix, Application etc.)
o Facility management (“fire alarms”, CCTV et.al.)
o Phones
Please keep in mind this must be handled carefully. In some networks, the function is somewhat reflected/expressed by the VLAN a specific system sits in (which is “topology information”). Now, if you assign an address hierarchy level for this (next to me I have plans from two different organizations both having assigned a /52 for a “PIN” or “Usage Type”) this could either lead to conflicts with the VLAN assignment scheme or the future VLAN assignment has to follow the plan (“topology follows addressing” as of Rekhter’s law).
Furthermore please note that in particular in Cisco literature/white papers the term “Place In the Network” (PIN) can be found for the latter category. Personally I don’t think that both the term or the way it’s (mis-) understood in Cisco’s customer space is particularly helpful.
Examples
In this section we’ll have a look at some (anonymized & alienated) real-life examples. It should be noted that these are not necessarily “good examples” (there’s no “one scheme fits all” approach. in the end of the day it’s all about understanding the above objectives and identifying/prioritizing those relevant for your organization), but just serve as a basis for some discussion.
What we commonly see in the type of organizations/networks I laid out in the first post is very much “topology-oriented”, for the simple reason that – paraphrasing Rekhter’s law again – “addressing follows topology”, read: those organizations already have (often complex) existent networks which are not going to be re-designed for IPv6. Going with a topology-oriented approach frequently supports the objective “allows for aggregation” and usually helps with “significance”, too.
Here’s the first one:
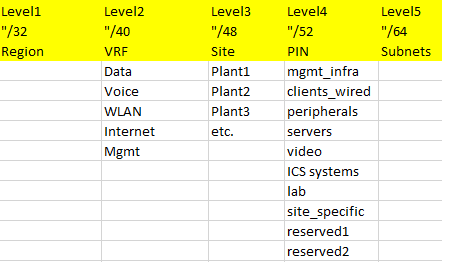
Some comments: from my perspective this is a nice, simple scheme, providing some flexibility and room for growth. Given the (prefix length-wise) high importance of the “PIN” such a scheme makes most sense when VLAN assignments are done along the lines of functions/system roles anyway.
===
Here’s a second example:
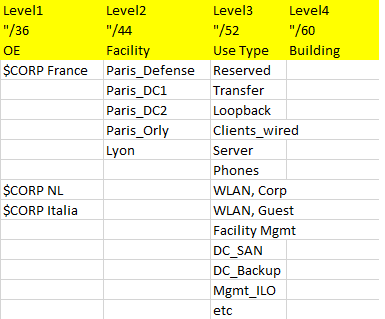
Personally, there are a number of things I don’t like about this one too much. These include:
– the /48 prefix length (which many people intuitively expect, see above) is missing. This might be confusing for some external consultants (not to think of PCI auditors looking for “segmentation” ;-), forgive me that one) coming into this environment in some part of the world, in 10 years.
– the high number (I’ve only displayed some) of “use types” might be confusing. Simplicity might not have been a main goal of this plan…
– not sure about the value of the “building” element. Who really benefits from this one? [it might be encoded in the VLAN(s) anyway]. What about the expected number of changes of “buildings” over time? [see discussion above]
===
And this is a third example:
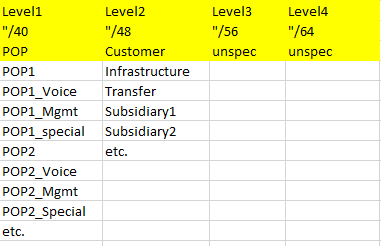
Again, some comments here:
– this organization is following the “painting by numbers” approach (see link above), hence the prefix lengths all being multiples of eight.
– while being a sufficiently large organization (+20K employees, yearly revenue ~ 3bn US$) there’s a high level of diversity & autonomy of individual business units, not least due to the fact that there’s many small(er) companies (legal entities on their own) assembled under one group’s roof. The network team responsible for the plan hence considers all the entities connected to the overall network as “customers” and “just hands out /48s to them”. If possible the “local” network team is made aware of the overall (“painting by numbers”) approach and some rough guidelines, but in the end of the day they can structure/sub-divide the /48 as they want. That’s where the “unspec” on hierarchy levels 3 and 4 comes from.
– they use the term “POP” for the main regional hubs, providing Internet breakout.
===
I hope the above discussion and samples can help you a bit when tackling the task for your own organization! Feel free to leave comments or dm us with suggestions or describing your own approach/experience.
Just one last thing for today (given this whole series originated from a post on the IPv6 Hackers Mailing List). You might have noted that we only covered the upper /64 bits of an IPv6 address. There’s a simple reason for this: from an address plan’s perspective you should never touch the IID’s /64 bit. In other words: do not encode any information in the right most 64 bits. Ever.
If you like we can discuss this in yet another post, some day.
Thanks for reading up until this point 😉 & have a good one everybody
Enno
Hi Enno,
just wanna leave a small note of my appreciation. Thank you for sharing some of your experiences and sharing some useful links (at least fpr a IPv6 n00bie like me). I also really liked your presentations on the IPv6 Kongress in FFM.
Heiko,
thanks! for the kind feedback and good to hear the stuff is useful.
We’d be even more delighted if next time you show up with an IPv6 address ;-))
[which, ofc, applies also to the connection I’m currently using…]
Best
Enno
Wow, this post is already 4 years old. Time flies by… 😉
Hey Enno. I just came back to this post and have one question about your last sentence: “You might have noted that we only covered the upper /64 bits of an IPv6 address. There’s a simple reason for this: from an address plan’s perspective you should never touch the IID’s /64 bit. In other words: do not encode any information in the right most 64 bits. Ever. If you like we can discuss this in yet another post, some day.”
–> Why?
Since I am indeed using some portions of the interface identifier (servers only!) for some kind of logic such as a serial-number/counter of my devices (next to last hextet) or the TCP/UDP port the device is listening on (last hextet). To my mind this is really useful since I can easily look at firewall logs and can recognize which devices are involved.
Hence I am really interested in your thought against such semantics. Thanks a lot.
Cheers,
Johannes
Hi Johannes,
thanks for the feedback.
> Wow, this post is already 4 years old. Time flies by… ?
Indeed. Even took me a while to respond 😉
And I consider much of what I write in that post as outdated in the interim, see also the “IPv6 Address Management – The First Five Years” (https://www.ernw.de/download/TR18_NGI_IPv6-Addr-Mgmt-First-5-Years.pdf) talk from last year’s Troopers.
As for your question: from my experience & perspective the main problem of the approach you lay out already becomes manifest in the personal pronoun that you use: “*I* do sth for *my* servers and *I* can hence derive conclusions from *my* log files”.
In practice many parties with very different roles might be involved in several task, incl.
– create a proper scheme (like your’s).
– communicate this scheme to $SERVER_OPS or (in many environments) more probable to $DATACENTER_PROVIDER, plus repeat this every 3-5 years after changing the latter.
– plan 6 months of discussion plus escalation to find a compromise between your scheme and the way $DATACENTER_PROVIDER usually does things. recognize that the perceived benefits of the scheme are already faded at this point/by said compromise.
– explain the scheme to the people looking at the logs, that is (at least one) yet-another party.
– find out that in the interim half of the servers are configured in a way different of the scheme as $DATACENTER_PROVIDER has sourced some tasks to yet another party, and the scheme got lost on the way.
– realize that $PEOPLE_LOOKING_AT_LOGS don’t have access to the CMDB containing the serial numbers and hence don’t rly get anything out of the information encoded in that part of the address.
– etc.
you get an idea 😉
In short, what we usually recommend nowadays wrt to IPv6 addressing is along the lines: “do whatever you want, but – if at all – encode information in the DNS name, and feed all information you have into the central IPAM system”. See discussion “prescriptive” vs. “descriptive” in this post:
https://insinuator.net/2016/02/ipv6-address-planning-in-2016-observations/
I hope this somewhat provides an answer to your question. Have a great weekend and see you at the #TR19 IPv6 track 😉
Enno