Although, more and more companies start to move their IT-Infrastructure from on-premise to public cloud solutions like Amazon Web Services (AWS) and Microsoft Azure, public cloud providers are not an option for every organization. This is where private cloud platforms come into play as they give organizations direct control over their information, can be more energy efficient than other on-premise hosting solutions, and offer companies the possibility to manage their data centers efficiently. OpenStack is a widely deployed, open-source private cloud platform many companies and universities use.
With companies and organizations moving their resources to the cloud, the security of the cloud deployment moves into focus. To ensure security in private and public cloud deployments, cloud security benchmarks are developed. The Center for Internet Security (CIS) maintains several benchmarks for public cloud providers like the AWS Foundations Benchmark or the Azure Foundations Benchmark.
As the number of deployed resources in cloud deployments can be extensive, tools for automated checking of these benchmarks are needed. Steampipe is such a tool. It offers automated checks for various cloud providers with good coverage of security standards and compliance benchmarks.
Since for OpenStack no Steampipe plugin existed, we implemented it. This blog post aims to provide a deeper understanding of how OpenStack and Steampipe work and how the Steampipe plugin for OpenStack can be used to query deployed cloud resources for insecure configuration via SQL.
TL;DR; In this blog post we present our Steampipe plugin for Openstack we’ve just released as open source. It can help you to automate checking your OpenStack resource configuration for common security flaws.
What is OpenStack?
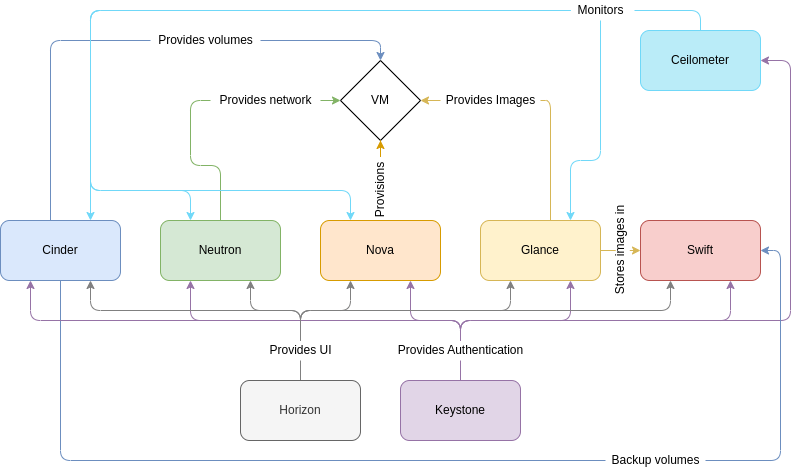
OpenStack is an open-sourced combination of software projects and is the most widely adopted open-source cloud computing platform. It is used to manage on-premise hardware resources and due to OpenStack’s modular and highly configurable architecture, it can be tailored to the available hardware resources without losing its scalability. You can think of it as AWS for your own data center.
OpenStack is split into several software components, which are separate software projects. Every software component serves a different purpose and a subset of all available software components is required to provide the core functionality of OpenStack. Further software components can be added to increase the overall functionality of the deployment. The primary components required to deploy OpenStack are keystone for Identity Access Management (IAM), nova for compute resources, cinder for storage resources, and neutron for network services.
Many software components of OpenStack can be managed via a REST-based API. The OpenStack service APIs can offer the functionality to list, create, delete or configure cloud resources. Since every OpenStack software component is a separate software project, every software component has its own API. All API endpoints of the deployed OpenStack software components are contained in the backend of keystone. With the help of a Steampipe plugin for OpenStack, those APIs can be used to extract the configuration data of deployed cloud resources.
What is Steampipe?
Steampipe Plugins
Steampipe Mods
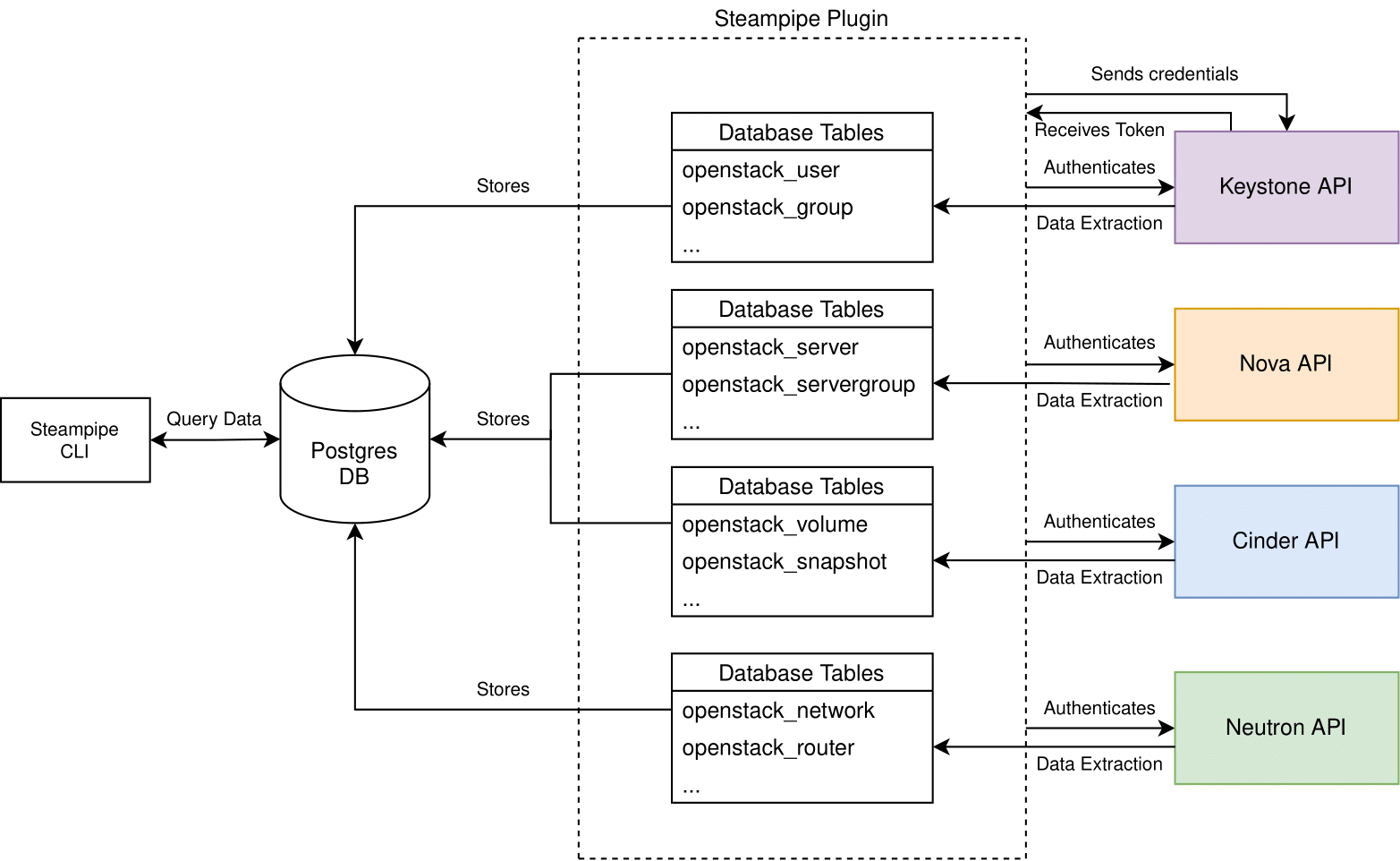
A Steampipe Plugin for OpenStack
The data is extracted by sending the token with every request to the respective API. If the token is valid, the requested data is returned and transformed into the desired data structure defined by the Steampipe plugin. In the last step, the data is stored in the Postgres DB.
How to Use
To use the Steampipe plugin, Steampipe first needs to be downloaded from the official website. After completing all described steps, the following command can be executed to install the OpenStack plugin for Steampipe:
$ steampipe plugin install ernw/openstack
After the OpenStack Steampipe plugin is installed, the connection to the OpenStack deployment needs to be configured. There is a configuration file located at ~/.steampipe/config/openstack.spc. In this file, the following connection parameters need to be set:
connection "openstack" {
plugin = "ernw/openstack"
# Authentication information
identity_endpoint = "https://example.com/identity/v3"
username = "admin"
password = "changeme"
domain_id = "default"
project_id = "3e666015f769bf30cda73a1a1e9b794a"
}
The connection parameters can also be set via environment variables as follows:
export OS_AUTH_URL=https://example.com/identity/v3 export OS_USERNAME=admin export OS_PASSWORD=changeme export OS_DOMAIN_ID=default export OS_PROJECT_ID=3e666015f769bf30cda73a1a1e9b794a
For more information about the available configuration parameters take a look at the official documentation.
After configuring the connection parameters, everything is setup to query your OpenStack deployment. Simply run the following command to enter the Steampipe CLI:
$ steampipe query
Run a simple query to check that everything works as expected:
select name, description, email, enabled from openstack_user;
+-------------------+---------------------------+-----------------------------+---------+ | name | description | email | enabled | +-------------------+---------------------------+-----------------------------+---------+ | demo | This is the demo user | demo@example.com | true | | admin | This is the admin user | admin@testproject.com | true | | reader | This is the readonly user | reader@testproject.com | true | +-------------------+---------------------------+-----------------------------+---------+
The plugin is very useful to check for security misconfigurations of deployed cloud resources e.g. The following query shows all users with no password expiry date set:
select name, description, email, enabled, lock_password, domain_id, password_expires_at, default_project_id from openstack_user where password_expires_at is null;
You can find all available tables documented here together with some example queries for each table.
Limitations
Currently, several limitations for the OpenStack Steampipe plugin exist. First, only the primary software components keystone, nova, neutron, and cinder are included. Moreover, as every software component has its own API, the versioning of those APIs differ. At the moment, the plugin uses the newest versions available, which can lead to backwards compatibility issues. Finally, not all data is extracted from the APIs but more and more tables will be implemented over time.
Outlook
In the future, more and more tables will be added to the Steampipe plugin for OpenStack. Besides more tables, Steampipe mods need to be created to automate the checking of common security flaws in the configuration of OpenStack cloud resources. This will be the next step to make the plugin even more usable. If you are interested in the project and you need more tables or mods, feel free to contribute or open an issue.
Cheers,
Gregor