Recently there has been quite some discussion about so-called neighbor cache exhaustion (“NCE”) attacks in the IPv6 world. This is Jeff Wheeler’s “classic paper” on the subject, my kind-of personal networking guru Ivan Pepelnjak blogged about it back some time, here‘s a related discussion on the IPv6 hackers mailing list and in March 2012 (only three months after the respective IETF draft’s version 0 was released) the RFC 6583 was published, covering various protection strategies.
In the run-up to this workshop I’ll give at the Troopers IPv6 Security Summit next week I decided to build a small lab to have a closer look at NCE, in order to be able to express reasonable statements during the workshop ;-).
This is the first part of a (presumably two part) series of blog posts presenting the lab results and potential mitigation approaches. In this first part I’ll mostly focus on the actual attacks & lab testing performed. I won’t explain the basic idea behind NCE, you might look at the above sources (in particular Jeff Wheeler’s presentation) to understand the way it is supposed to work and to cause harm.
Actually the lab setup was quite simple. The lab was composed of a layer 3 device (mainly a Cisco 1921 router running an IOS 15.1(4)M3 image, but this got temporarily replaced by others, see below) connecting two segments, a “good” one hosting two physical systems (e.g. to be considered members of a fictional DMZ) and a “bad” segment with an attacker system. Essentially the only requirement was that all connections (attacker’s system’s NIC to switch & switch to all router interfaces involved) were at Gbit speed to simulate an attacker coming in from a high speed Internet link. [yes, I’m well aware that a 1921 can’t really push traffic at Gbit speed ;-)]
Besides the necessary basic IPv6 addressing config, the router was mostly in default state, so no tweaking of any parameters had taken place.
Here’s a simple diagram of the setup, together with some addressing information.

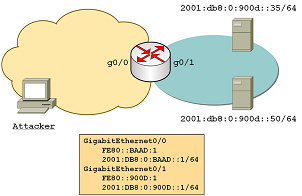{kind=link}
The testing was, again, quite simple:
a) scan /64 “good” segment with potentially high speed from attacker’s system, in order to eventually exhaust neighbor cache on L3 device by high number of INCOMPLETE entries. Therefore I used “alive6” from the THC suite and “scan6” from the IPv6 toolkit, on an Ubuntu system (HP Elitebook 2570p with an i7-3520M CPU @ 2.90GHz and 8 GB RAM, running a 3.5.0-17-generic kernel).
The “attacks” looked like:
root@mobile32# ./alive6 eth0 2001:db8:0:900d::1-ffff:1-ffff and
root@mobile32# ./scan6 -i eth0 -d 2001:db8:0:900d::1-ffff:1-ffff
providing output similar to
2001:db8:0:900d::1
2001:db8:0:900d::35
2001:db8:0:900d::50
b) during attack constantly monitor state of neighbor cache on L3 device, both by looking at the actual cache by “show ipv6 neighbor” and looking at the cache’s size by “sh ipv6 ne stat”. (all this performed on a console session).
c) in parallel occasionally try to reach (ping) systems in “good” segment.
Now, as for the results, here’s some surprise (or maybe not, see discussion below): I did not manage to exhaust the neighbor cache at all, I didn’t even get close to that.
Usually I generated about 1K (ICMPv6 type 128, that is a ping in IPv6) packets per second. I could see this is in a local tcpdump, supported by rough numbers from looking at ntop data. I can confirm that associated neighbor solicitations (“NS” packets, ICMPv6 type 135) left the router’s “good” interface (had a span port configured on the switch, connected to yet another system not involved in the attack on any side). Furthermore I could observe quite some ICMPv6 NS traffic on the router console (fully aware that being connected to a 9600 Baud console session will not cope with displaying full debug info here…).
BUT: the number of entries in the device’s neighbor cache did not exceed (512 + number of reachable/stale entries related to “legitimate IPv6 members of 900d segment”) entries at any given point of time. Clearly this did not exhaust the neighbor cache and the systems in the 900d segment remained reachable all the time.
Here’s some sample output from the router’s console during the attack:
L3_Device#sh ipv6 ne stat
IPv6 ND Statistics
Entries 519, High-water 519, Gleaned 5, Scavenged 0, Static 0
Entry States
INCMP 512 REACH 4 STALE 3 GLEAN 0 DELAY 0 PROBE 0
Resolutions
Requested 2050, timeouts 4608, resolved 2, failed 1536
In-progress 512, High-water 512, Throttled 992, Data discards
with a detailed output of the neighbor cache looking like this:
L3_Device#sh ipv6 ne
IPv6 Address Age Link-layer Addr State Interface
2001:DB8:0:900D::1:1DB5 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1CB5 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1DB4 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1CB4 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1DB7 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1CB7 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1DB6 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1CB6 0 – INCMP Gi0/1
2001:DB8:0:900D::1:1DB1 0 – INCMP Gi0/1
[…]
So what could be the reason for this (which somewhat contradicts the way the attack vector is usually described)?
First I assumed that, given the 1921’s image supports the “ipv6 nd cache interface-limit” command (we’ll get back to this one in the second part of this series), there might be some default value for it. However I couldn’t find any info on this on cisco.com and couldn’t determine it from a “show run all” either. Does anybody know if there’s a default and, of course, which value that is? 😉
That’s why I replaced the 1921 with a much older 1812 running IOS 12.4(22)T, compiled in Oct 2008 and not having the cache interface-limit command. Same results.
(Furthermore I tried it with a first generation WS-C3560-8PC running 15.0(1)SE as well).
And I tried setting the cache interface-limit to a much higher value, in the interim back on the 1921. Again, same result: number of INCOMPLETE cache entries never got any higher than 512.
Admitted I did not try any other device than those three Ciscos, that is no Juniper router, no Solaris/BSD/Linux based router or anything. So these might behave completely differently and I’m happy to get any feedback on practical testing with those. Let me know…
It seems that Cisco devices (even relatively old ones) somehow internally manage the neighbor cache in a way that limits the number of INCOMPLETE entries to those pesky 512. Which would then easily defeat NCE attacks, even in a default config.
Still, all this is pure speculation and I hence returned to the good ole “read the RFCs, Luke” approach. So what does the main RFC on neighbor discovery, that is RFC 4861, tell us as for the way neighbor discovery works in general and the neighbor cache is maintained in particular?
The RFC’s section “7.2.2. Sending Neighbor Solicitations” states
“When a node has a unicast packet to send to a neighbor, but does not
know the neighbor’s link-layer address, it performs address
resolution. For multicast-capable interfaces, this entails creating
a Neighbor Cache entry in the INCOMPLETE state and transmitting a
Neighbor Solicitation message targeted at the neighbor. […]
While awaiting a response, the sender SHOULD retransmit Neighbor
Solicitation messages approximately every RetransTimer milliseconds,
even in the absence of additional traffic to the neighbor. […]
If no Neighbor Advertisement is received after MAX_MULTICAST_SOLICIT
solicitations, address resolution has failed.”
which then, according to section “7.3.3. Node Behavior” means that
“If address resolution fails, the entry SHOULD be deleted”.
Taking into account that the RFC 4861 assumes a RETRANS_TIMER default value of 1000 milliseconds and a MAX_MULTICAST_SOLICIT default value of 3 transmissions (for both values see section 10 of the RFC), potentially a neighbor cache entry in INCOMPLETE state gets deleted after 3 seconds (at least on systems whose IPv6 stacks follow RFC 4861 as for their neighbor discovery algorithms).
Which in turn could easily explain the observed behavior of numerous INCOMPLETE state entries getting quickly deleted on the Cisco L3 devices examined. Additionally we can see from the following sample output of “sh ipv6 ne stat” output
L3_Device>sh ipv6 ne sta
IPv6 ND Statistics
Entries 7, High-water 519, Gleaned 5, Scavenged 0, Static 0
Entry States
INCMP 0 REACH 2 STALE 4 GLEAN 0 DELAY 1 PROBE 0
Resolutions
Requested 293639, timeouts 880908, resolved 3, failed 293636
that actually the number of timeouts = approx. 3 * Requested which further supports the hypothesis derived from the RFC, that is INCOMPLETE entries getting deleted after three failed NS requests.
One of the main assumptions Jeff Wheeler makes in his presentation on the subject is that “NDP expiration time is long, like ARP” (see slide 10 in his presentation). Honestly I think that – for INCOMPLETE entries – this assumption is plain wrong (sorry, Jeff! I concede you might have tested much more and different equipment than I’ve tested), based on the actual observations in my lab and my understanding of the relevant sections of RFC 4861.
What does this mean in practice? For the moment I conclude that NCE might be an overestimated risk as for its actual impact. Again: I would be happy to learn that I just overlooked something (and things are different than they seem to me) or that my (Cisco only) set of test devices just represent “an unfortunate sample set”. If that’s the case pls somebody let me know.
And, of course, it might still be prudent (and constitute due diligence) to take preventative measures against NCE. Which I’ll discuss in the next post 😉
have a good one everybody
Enno
Hi Enno, good work. Would be interesting to see if anyone manage to exhaust nc with a similar setup on other devices. But I understood from Eric Vynckes talks that Cisco itself is vulnerable and they are working on a countermeasure they call “IPv6 Destination Guard”.
Cheers from Switzerland
Frank
Actually, what I meant to say is that ‘destination guard’ is the silver bullet to mitigate this attack (i.e. router never initiates a NS for unknown IPv6 address, it only refreshes existing ones), but, usually, the normal thresholds are OK for most deployments.
Thanks for the testing BTW
-éric
Great article Enno. Thanks for sharing your test results. Your explanation seems very reasonable to me.
I believe that in order this attack to be effective, the “malicious” packets should arrive even faster from several distributed sources at the same time (aka DDoS), which, of course, it doesn’t make it that trivial attack. Nevertheless, this would be a rather typical DDoS flooding attack which could take down the target for other reasons too.
Unless, as you said, we miss something…
Thank you for your work. I was wondering if you looked at an internal attack. For instance. A workstation that has a virus that cycles the source address. I have even heard of devices wanting to cycle addresses and/or mac addresses for privacy or security reasons. Having a client cycle the source address would not leave incomplete entries but actual valid entries.
Hopefully someone can tell me I am worrying about things that don’t matter.
Thanks again.
Hi Enno. I have performed similar tests with alive6 against FreeBSD, OpenBSD and Ubuntu. My results mirror yours. I could get the neighbor cache to fill up to a certain point, but it stabilized at somewhere well below exhaustion (~2k entries).
I have not tested a combined attack where an outside attacker has an accomplice inside the network that answers all the neighbor solicitations. Guess that would be similar to what Mark mentioned.